
이 글에서는 2022년 구글에서 발표한 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models에 대해 살펴볼 예정이다.
본 논문은 2022년 NeurIPS에 등재된 상태이며, 2023년 7월 현재 인용 수는 940회이다.
논문 링크: https://arxiv.org/abs/2201.11903
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
We explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models to perform complex reasoning. In particular, we show how such reasoning abilities emerge naturally in su
arxiv.org
0. Abstract
(1) 본 논문에서 제시하는 Chain of Thought Prompting방식을 사용하면 LLM의 성능을 효과적으로 올릴 수 있다.
(2) 특히 산술, 상식, 기호적 추론(symbolic reasoning) 분야에서 성능 향상을 보여주었다.
*기호적 추론 태스크의 예시는 다음과 같다 : 'he is raising star'라는 문장이 있을 때 각 단어의 끝 단어만 다시 나열해줘 -> 'esgr'
(3) 예를 들면, CoT(Chain of Thought)를 이용한 PaLM 540B모델이 수학 벤치마크에서 제일 좋은 성능(SOTA)를 보여주었으며, 심지어 파인튜닝한 GPT-3보다 더 좋은 성능을 보여주었다.
1. Introduction
*(0) 이 파트에서는 본 연구에 영향을 준 연구와 사용한 방법론 및 장점에 대해 간단하게 소개한다.
(1) NLP에서 성능을 향상시키는 방법으로, 모델의 사이즈를 향상시키는 방법이 계속적으로 제시되어 왔다.
(2) 그러나 모델의 크기를 향상시키는 것만으로 모든 태스크에서 항상 좋은 성능을 내지는 못했다.
- 성능을 올리기 힘들었던 분야에는 앞서 언급한 산술, 상식, 기호적 추론(symbolic reasoning) 분야가 있다.
(3) 본 연구에 영감을 준 이전 연구는 아래와 같이 두 갈래로 나눌 수 있다.
a. 산술 문제를 풀 때, 모델이 단순히 답만 생성해내도록 하는 것이 아닌, 이론적 근거(rationales)도 생성해내도록 함으로써 성능을 높일 수 있었다.
b. LLM은 prompting을 통해 in-context few-shot learning을 할 수 있으며, 이 방법을 통해 성능을 높이는 다양한 방법들이 제시되고 있다.
*즉 specific한 태스크를 수행할 때, 전체 파라미터를 파인 튜닝하는 대신 태스크에 맞는 prompt를 input에 같이 제공해 prompt만 튜닝하는 방법을 사용할 수 있다.
(4) 그러나, 앞선 방법들에는 각각 지대한 문제가 있다.
a. 이론적 근거(rationales)를 생성해내도록 하는 방법의 문제점은 양질의 이론적 근거(rationales)를 사람이 직접 만들어 넣어줘야한다는 것이다.
b. LLM에서 prompting의 문제점은 prompting이 추론 태스크에서는 성능을 잘 높이지 못 한다는 것이다.
(5) 본 논문에서는 두 방법을 섞어 각각의 단점은 줄이고, 장점만 취하는 방법을 제시하고자 한다.
*즉 prompting을 사용하되, 적절한 promt를 통해 모델이 답 뿐만아니라 이론적 근거도 추론할 수 있도록 하고자 한다.
(6) 구체적으로 본 논문에서는 추론 태스크에서 few-shot prompting의 가능성을 연구했고, 사용한 promt는 다음과 같은 형식이다.
<input, chain of thought, output>
(7) 본 연구에서 사용한 위와 같은 방법을 chain-of-thought prompting이라 부르기로 한다.
(8) chain-of-thought prompting의 예시는 아래와 같다.
*파랑색으로 하이라이트된 부분이 CoT(Chain of Thought)라 볼 수 있으며, CoT를 사용한 경우에만 수학 문제의 답을 맞춘 것을 알 수 있다.
(9) 산술, 상식, 기호적 추론 세 가지 태스크에서 chain-of-thought prompting이 기존 prompting의 성능보다 좋았다.
(10) 본 연구에서 사용한 chain-of-thought prompting같이, prompting만으로 성능을 높이는 방법론은 매우 가치가 있다.
- 좋은 prompt를 이용한다면 비교적 적은 dataset만으로도 좋은 성능을 낼 수 있기 때문에 효율적이다.
- 특정 태스크에서 성능이 좋은 prompt가 범용적인 prompt라면, 이 prompt를 다양한 태스크에 적용해 좋은 성능을 낼 수 있다.
2. Chain-of-Thought Prompting
(1) 논문의 목적은 language model이 chain of thought prompt처럼 최종 결과를 생성할 때 필요한 중간 과정 및 추론 과정 역시 모델 스스로 생성할 수 있도록 하는 것이다.
(2) 이 논문에서는 chain-of-thought 형식의 prompt를 조금만 few-shot으로 제공해주면 모델이 스스로 chain-of-thought를 생성할 수 있음을 보일 것이다.
(3) chain-of-thought prompting이 추론 태스크에서 좋은 성능을 내는 까닭 다음과 같은 특징 때문이다.
a. chain of thought를 통해 문제 푸는 과정을 단계별로 분해해 추론할 수 있게 해주며, 이를 통해 태스크 해결에 추가적인 연산을 할당할 수 있게(additional computation can be allocated)한다.
b. chain of thought를 통해 모델의 출력 결과에 대해 해석가능성을 부여한다. 만약 모델이 틀린 답을 내놓았을 경우에도 어느 부분에서 잘못된 결과를 도출했는지 찾기(debug) 쉬워진다.
c. chain of thought 방식의 추론은 산술 추론 태스크, 상식 추론 태스크 등의 태스크 뿐만 아니라 사람이 해결하고자 하는 대부분의 태스크에 적용 가능하다.
d. chain of thought 방식의 추론은 현재 상용화된 language model에 손쉽게 적용시킬 수 있다.
(4) 이제 아래의 3, 4, 5 Section에서 산술 추론, 상식 추론, 기호적 추론(symbolic reasoning)에 각각 chain-of-thought prompting을 활용하는 것을 볼 것이다.
3. Arithmetic Reasoning
3.1 Experimental Setup
(1) Standard prompting과 Chain-of-thought prompting
a. standard prompting은 few-shot prompting을 의미한다. (위 figure에서 왼쪽에 해당)
b. chain-of-thought prompting은 standard prompting에 chain of thought를 추가한 것이다. (위 figure에서 오른쪽에 해당)
(2) 총 4개의 벤치마크 데이터셋(GSM8K, SVAMP, ASDiv, AQuA, MAWPS)에 대해 실험을 진행했는데, 정확한 비교를 위해 chain-of-thought prompt를 만들 때 같은 입력에 대해 여러 명의 사람이 서로 다른 prompt를 만들고 하나를 골라서 사용했다.
(3) 평가는 다섯 개의 모델을 이용해 진행했다.
- GPT-3 (350M, 1.3B, 6.7B, 175B)
- LaMDA (422M, 2B, 8B, 68B, 137B)
- PaLM (8B, 62B, 540B)
- UL2 20B
- Codex
3.2 Results
(4) 주요 결과는 아래의 figure와 같다.
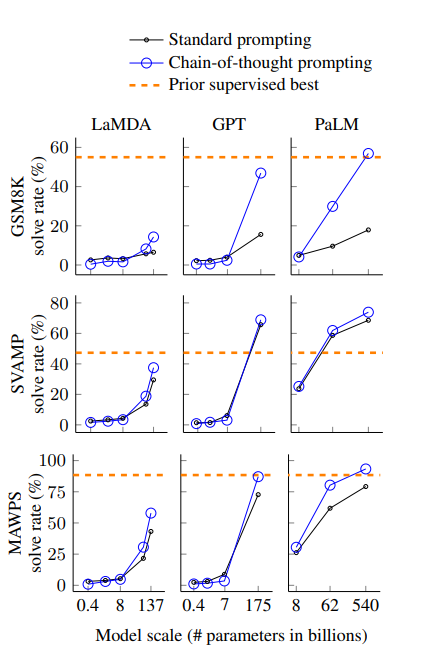
(5) 결과에서 알 수 있는 점은, 모델의 스케일이 커질수록 CoT(Chain of Thought)의 성능이 잘 나타난다는 것이다.
(6) 더하여, CoT는 복잡한 문제에 적용했을 때, 그 성능이 더 잘 나타났다. 반대로 쉬운 문제(태스크)를 할 때는 Standard prompting과 비교하여 성능이 감소하거나 적게 증가하는 모습을 보였다.
(7) PaLM 540B 모델의 경우에는 평가한 벤치마크 테스트에서 가장 좋은 성능(SOTA)를 보였다.
(8) CoT가 어떻게 작동하는지 알아보기 위해 문제를 푸는 과정에서 모델이 생성해낸 CoT를 분석해 보았다.
- 맞춘 문제 중 50개를 살펴보니, 단 2문제만 모델이 생성한 CoT에 오류가 있었으며, 나머지 문제에 대해서는 정답과 CoT에 포함된 추론 과정 역시 정확했다.
- 틀린 문제 중 50개를 살펴보니 46%의 문제는 CoT 추론 과정에서 오류가 없거나 사소한 것만 있었고, 나머지 54%의 문제는 CoT의 추론 과정에서 중요한 오류가 있었다.
(9) 흥미로운 것은 적은 파라미터 수를 가지는 모델에서 틀린 문제를 똑같은 모델에 파라미터 수만 증가시키니 정확한 CoT 추론과 함께 맞출 수 있었다. (PaLM 62B <-> PaLM 540B)
3.3 Ablation Study
(1) 본 연구에서는 CoT가 왜 성능을 높여주는지 알아보기 위해 여러 조건들을 바꿔가보며 추가적인 실험을 진행했다.
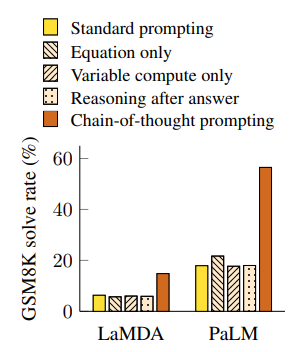
(2) Equation only : CoT를 자연어로 제공하는 것이 아닌 수식만 제공하는 방식을 사용해 성능을 테스트
- 수식만을 사용하니 비교적 복잡한 태스크에서는 성능이 좋지 않았지만, 조금 더 쉬운 태스크에서는 좋은 성능을 보였다.
(3) Variable compute only : CoT를 이용한 것이 성능이 잘 나오는게, Standard prompting 때보다 토큰 수가 늘어나 연산량이 증가한 것이 원인이 아닐까 생각해 Standard prompting에서도 '...'을 넣어 CoT 때와 토큰 수를 똑같이 맞춰주었다.
- 토큰 수를 똑같이 맞춰 연산량을 맞춰 주었는데, 여전히 CoT가 성능이 좋았다.
(4) Chain of thought after answer : CoT를 이용한 것이 성능이 잘 나오는게 CoT가 추론 과정에서 도움을 주는 것이 아닌 단순히 관련된 정보(relevant knowledge)를 더 많이 줬기 때문인가 생각해 CoT prompt를 answer 이후에 넣고 학습을 시켜보았다.
- 그 결과, CoT prompting을 맨 마지막에 준 것은 기존의 standard prompting과 성능이 유사했으며, 이는 추론 과정 중간에 CoT prompting을 사용하는 것이 도움이 된다는 것이다.
3.4 Robustness of Chain of Thought
(1) GPT-3의 SST-2 벤치마크 데이터셋에 대한 테스트에서는 *exemplar가 만든 prompt의 차이에 따라 성능이 54.3%에서 93.4%까지 차이가 났다고 한다.
*exemplar는 few-shot prompt, cot prompt 등을 만들어주는 사람을 의미
(2) 본 연구에서도 여러 exemplar의 prompt를 이용해 각각 학습을 해본 결과, 모든 상황에서 기존의 standard prompt보다 성능이 좋았다.
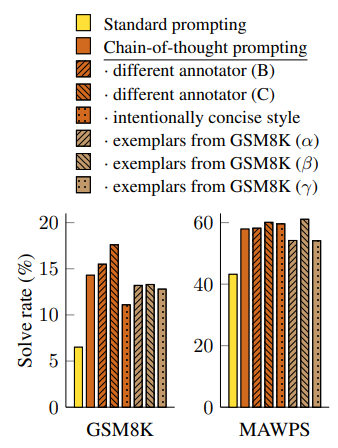
(3) 즉 annotator(= exemplar)에 대해 CoT는 robustness를 가진다고 할 수 있으며, 앞서 보았듯이 여러 다른 모델에서도 CoT가 좋은 성능을 냈으므로 모델에 대해서도 robustness를 가진다 볼 수 있다.
4. Commonsense Reasoning
(1) 상식 태스크에서는 다섯 개의 벤치마크 데이터셋을 평가에 사용하였다.
- CSQA
- StrategyQA
- BIG bench : Date
- BIG bench : Sports
- SayCan
(2) 결과는 다음과 같다.
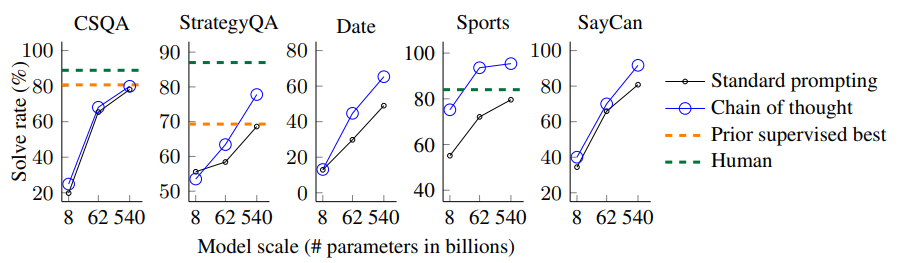
- 위 figure의 결과는 PaLM 모델에 적용한 결과이다.
- 모든 태스크에서 모델 사이즈를 증가시키는 것이 성능을 향상시켰으며, PaLM 540B 모델은 기존의 최고 성능(SOTA)을 뛰어 넘는 성능을 보여주었다.
5. Symbolic Reasoning
(1) Symbolic Reasoning의 특징은 사람은 풀기 쉽지만 언어 모델은 풀기 어려운 문제들이라는 것이다.
(2) Symbolic Reasoning에서 사용한 태스크는 크게 두 가지로 나눌 수 있다.
a. Last letter concatenation
- 문장에 있는 단어들의 끝 문자만 모으는 것 (ex. "Amy Brown" -> "yn")
- 사람의 이름 데이터를 활용해 무작위로 섞어 데이터를 만들었다고 밝혔다.
b. Coin flip
- 동전이 있을 때, 동전의 초기 상태가 주어지고 동전이 몇 번 뒤집어졌는지 정보를 준 뒤, 마지막 동전의 상태를 맞추는 태스크
(3) 결과는 다음과 같다.
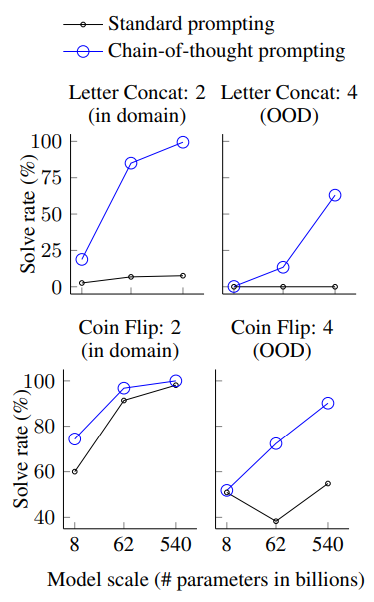
(4) PaLM 540B 모델에서 거의 100%로 문제를 맞췄다.
(5) 그러나 작은 크기의 모델은 여전히 떨어지는 정답률을 갖는 것으로 보아, 적어도 100B 크기의 모델 파라미터는 가져야 좋은 성능을 낼 수 있을 것이라 연구는 밝히고 있다.
6. Discussion
(1) CoT를 이용한 prompting은 세 가지 분야(산술, 상식, 기호적 추론)에서 좋은 성능을 낸다.
(2) 심지어 annotator와 모델에 대해서도 robustness를 가진다.
(3) 본 연구를 통해 새로운 의문점도 생기는데, 만약 모델의 크기를 더욱 키운다면, 추론 능력을 더 향상시킬 수 있을까 하는 것이다.
(4) 한계점으로는 neural network가 정말로 인간의 추론 과정을 흉내냈다고 볼 수 것인지에 대한 대답을 내놓을 수는 없다는 것이다.
(5) 또, CoT 추론이 좋은 성능을 내는 것이 큰 모델에만 한정되는 것도 한계점이라 밝히고 있다.
- 지금까지 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 논문에 대해 살펴보았다.
- 최근에는 적은 파라미터를 효과적으로 튜닝하는 방법(PEFT)을 소개하는 논문이나, 매우 큰 모델에서 주요한 정보는 사실 low dimension에 위치한다(intrinsic dimension)는 취지의 논문 등을 자주 보았다.
- 그래서 모델 크기는 더 안 키워도 되지 않을까 생각을 했었는데, 이 논문을 보니 모델의 사이즈를 더 키워보는 노력도 필요할 것 같다는 생각이 들었다.
- 실제로 논문에서 언급한 것처럼 실험한 모델들 중 가장 많은 파라미터수를 가진 PaLM 540B가 제일 좋은 성능을 냈으니 이와 관련된 연구가 더 많이 있을 것이라 생각한다.
'Natural Language Processing' 카테고리의 다른 글
| [논문 리뷰] PromptBERT: Improving BERT Sentence Embeddings with Prompts (0) | 2023.07.13 |
|---|---|
| [논문 리뷰] LoRA: Low-Rank Adaptaion of Large Language Models (0) | 2023.06.18 |
| [논문 리뷰] LIMA: Less Is More for Alignment (2) | 2023.05.23 |
| [논문 리뷰] InstructGPT: Training language models to follow instructions with human feedback (2) | 2023.04.28 |