
이 글에서는 InstructGPT를 제안한 논문인 Training language models to follow instructions with human feedback에 대해 살펴볼 것이다.
본 논문은 GPT-1, GPT-2, GPT-3 논문을 발표한 OpenAI로부터 2022년 NeurIPS에 발표되었다.
논문 링크: https://arxiv.org/abs/2203.02155
Training language models to follow instructions with human feedback
Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not ali
arxiv.org
1. Introduction
Large Language models (LMs)는 학습 가능한 파라미터 수를 증가시키는 쪽으로 발전시켜왔으며, 실제로 학습 가능한 파라미터 수가 증가할수록 모델의 성능이 증가함이 밝혀졌다 (Brown et al., 2020).
그러나 이러한 모델이 public NLP datasets에 대한 객관적인 성능은 증가할지 몰라도 인간의 의도를 잘 반영하고 있지는 못한다고 논문에서 밝히고 있다.
인간의 의도를 잘 반영하고 있지 않다는 의미로 논문에서는 'misaligned'라는 단어를 썼는데 다음과 같은 상황을 의미한다.
(1) 사실이 아닌 정보를 사실인것처럼 생성함 (Untruthful)
(2) 유해한 정보를 생성함 (Toxic)
(3) 유저에게 도움되는 정보를 생성해내지 못함 (Not helpful to user)
이런 문제가 발생하는 이유로 논문에서는 기존의 LMs이 단순히 인터넷에 있는 텍스트 데이터셋에 대해 다음 토큰을 예측하는 학습만 하기 때문이라고 말한다. 그리고 'misaligned' 문제를 해결하기 위해 Reinforcement Learning from Human Feedback (RLHF; Christiano et al., 2017; Stiennon et al., 2020)을 이용해 GPT-3를 파인튜닝 했다고 밝히고 있다.
'We first hire a team of 40 contractors to label our data, based on their performance on a screening test.'
'Our aim was to select a group of labelers who were sensitive to the preferences of different demographic groups, and who were good at identifying outputs that were potentially harmful.'
특히 RLHF를 위해 InstructGPT에서는 데이터에 라벨을 달아주는 40명의 라벨러들을 직접 고용해 데이터셋을 직접 제작했으며, 다양한 내용의 텍스트에 대해 다양한 답변을 얻기 위해 인구통계학적인 특성을 고려해 라벨러들을 선정했다고 한다. 또 별도의 과정을 거쳐서 유해하지 않은 답변을 더 잘 생성하는 라벨러들을 선별했다고 밝히고 있다. 본 논문에서는 라벨러가 두 상황에 참여하는데, 아래와 같다.
(1) 모델을 학습시킬 이상적인 (질문 / 답변) 데이터셋을 생성하는 것
(2) 모델이 입력 문장에 대해 여러 출력 문장을 생성해낼 때, 출력 문장들에 대해 순위를 매기는 것
InstructGPT의 학습 과정을 간단히 요약하면 (1)을 통해 GPT-3 모델을 파인 튜닝시킨 Supervised fine-tuning (SFT)모델을 만든 뒤, 이 SFT 모델을 (2)를 이용해 한 번 더 학습시킨 것이다.
두 번째 학습에 대해 조금 더 자세히 설명하자면 SFT 모델이 생성한 Text의 점수를 매기는 Reward model (RM)을 만든 뒤, 이 모델을 학습시킬 때 (2)를 이용한다. 이를 통해 RM은 SFT 모델이 생성한 문장이 인간의 선호를 잘 반영할 때 높은 reward를 반환하는 모델이 된다. 그 후 SFT 모델을 베이스로 학습된 RM을 이용해 Reinforcement learning을 진행한다. Reinforcement learning의 목표는 reward를 최대화하도록 하는 것이므로 결국 모델이 인간의 선호를 잘 반영하게 되는 것이다.
즉, GPT-3를 기반으로 SFT와 RL이라는 두 단계를 통해 파인 튜닝 시킨 것이 InstructGPT이다. 논문에서는 1.3B / 6B / 175B 세 가지 크기로 InstructGPT를 학습시켰으며, GPT-3와 비교했을 때, 175B개의 파라미터 수를 가진 GPT-3 모델보다 1.3B개의 파라미터 수를 가진 InstructGPT가 더 좋은 성능을 낸다고 주장한다.
그럼 지금부터 InstructGPT의 자세한 학습 방법에 대해 알아보자.
2. Approach
우선 학습에 사용된 데이터셋부터 살펴보고, 이어서 모델을 살펴볼 것이다.
Dataset
학습에 사용된 데이터셋은 두 가지로 나눌 수 있다.
(1) 라벨러들이 작성한 프롬프트 데이터셋
(2) 유저가 OpenAI 사이트에서 기존의 모델을 사용하며 생성한 프롬프트 데이터셋
여기서 프롬프트 데이터셋이란, '다양한 토픽과 주제에 대한 [질문 / 답변], [명령 / 답변], [제안 / 답변] 등의 형태로 구성된 텍스트 데이터셋을 의미한다. 프롬프트의 예시는 아래와 같은 것이 있다. 이러한 프롬프트와, 프롬프트에 대한 답변이 쌍으로 있으면 프롬프트 데이터가 되는 것으로 볼 수 있다.
프롬프트의 예시 :
점심으로 먹을 음식 5개만 리스트 뽑아줘
인생에 대한 짧은 시를 써줘
인공지능 토끼에 대한 랩을 써줘
(1) 라벨러들이 작성한 프롬프트 데이터셋에 대한 설명이다. 이에 따르면 라벨러들은 세 가지 종류의 프롬프트 데이터를 만들었다.
Plain : 여러 주제에 대해 형식에 구애받지 않고 자유롭게 작성
Few-shot : 지시 형식으로 작성한 뒤, 그에 관한 몇 가지 예시를 같이 작성
User-based : 기존의 유저들이 OpenAI 사이트에서 작성한 프롬프트를 참고해 작성
모든 라벨러들에게 질문이 주어지면 가장 최선의 답변을 작성하여 프롬프트 데이터를 만들도록 지시했으며, 불명확한 질문에 대해서는 답변하지 않고 넘길 것을 요청했다고 한다. 또 라벨러들이 의도치 않게 사실과 다른 답변이나, 유해한 답변을 생성할 것을 대비해 별도의 지시 사항이 적힌 가이드도 제공했다고 한다.
(2) 유저가 OpenAI 사이트에서 작성한 데이터셋의 분포 및 예시는 아래와 같이 밝히고 있다.
또 학습에 사용된 전체적인 데이터셋의 크기는 다음과 같다.
여기서 SFT는 Supervised fine tuning을 의미하고, RM은 Reward model을, PPO는 Proximal policy optimization이다. PPO는 InstructGPT에 사용된 Reinforcement Learning 방법을 의미한다. 또 labeler는 고용된 라벨러를 의미하며, customer는 OpenAI 사이트에서 모델을 사용한 유저를 의미한다.
'For the RM, recall that for every prompt, we collected rankings for K outputs (ranging from 4 to 9) and trained the model on all KC2, so the number of ranked pairs we trained the model on is an order of magnitude larger than the number of prompts.'
'For SFT, note that we have many more labeler-written prompts than customer prompts—this is because, at the start of the project, we had labelers write instructions with a user interface that asked them to give an overarching template instruction as well as few-shot examples for that instruction'
SFT 학습으로 약 12k개의 데이터셋이 사용되었으며, RM 학습에는 약 32k개, PPO 학습에는 약 31k개의 데이터셋이 사용되었다. 여기서 RM을 학습할 때는 한 모델이 생성한 여러 문장 간의 비교 순위를 매기는 작업이 필요하므로 RM에서 데이터의 실제 크기는 더 클 수 있다고 언급한다.
더하여 데이터셋에 대한 다른 특징으로는 SFT 학습에서는 라벨러가 생성한 데이터가 유저가 생성한 것보다 더 많고, RM과 PPO에서는 유저가 생성한 데이터셋이 라벨러가 생성한 것보다 더 많다.
SFT에서 라벨러가 생성한 데이터가 더 많은 이유로 논문에서는 프롬프트의 형식을 잘 학습하기 위해서이다. 유저가 생성한 데이터보다 라벨러가 생성한 데이터가 조금 더 정제된 프롬프트 데이터일 확률이 높고, 또 라벨러가 몇 가지 예시와 함께 프롬프트를 제시한 문장(few-show examples)에 대한 데이터도 만들었기 때문에 이것을 이용한 양질의 학습을 할 수 있게 하기 위해 의도한 것이라 한다.
논문에는 학습에 사용된 프롬프트 데이터셋의 96% 이상이 영어로 쓰여졌으나 모델의 성능을 테스트 할 때는 다른 언어도 사용했으며 프로그래밍 언어로 된 문제도 테스트했다고 언급한다.
Models
학습에 사용된 모델은 세 가지로 분류할 수 있다. 앞서 언급한 것처럼 Step 1) Supervised fine tuning, Step 2) Reward model, Step 3) Proximal policy optimization이 그것이다. 논문에서 제시한 전체적인 모델의 구조는 다음과 같다.
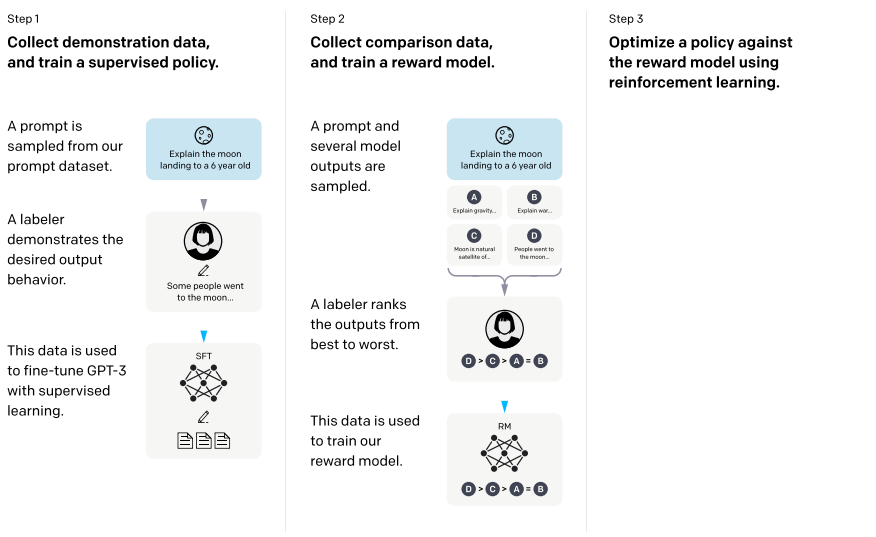
각 단계별로 살펴보자.
Step 1. Supvervised fine-tuning (SFT)
Supervised fine-tuning, 말 그대로 지도학습을 이용한 파인 튜닝이다. 라벨러들이 제작한 프롬프트 데이터셋을 이용해 GPT-3를 파인 튜닝하는 학습이다.
'We find that our SFT models overfit on validation loss after 1 epoch; however, we find that training for more epochs helps both the RM score and human preference ratings, despite this overfitting.'
SFT 학습과 관련해서 논문에서 다루는 내용 다음과 같다. 총 16 epochs를 학습시켰으며, cosine learning rate decay를 사용했고, 0.2의 residual dropout을 사용했다고 언급하고 있다. 또 1 epoch 뒤에 SFT가 overfit 되었지만 더 학습시키니 더 좋은 결과가 나온다고도 언급한다.
본 논문에서 SFT가 어떤 방식을 통해 학습되었는지 정확히 공개하지는 않았다. 하지만 SFT의 목적을 생각해보면 어떤 식으로 학습될 지 대략적인 감은 잡을 수 있다. 결국 입력 문장(여기서 입력 문장의 형식은 당연히 프롬프트 형식이다.)이 들어왔을 때, 그에 대한 모델이 만든 출력 문장이 라벨러가 만든 이상적인 답변 문장과 유사해지도록 학습하지 않을까 유추할 수 있다.
Supervised fine-tuning이라는 말은 본 논문을 작성한 OpenAI의 다른 논문 중 GPT-1을 제시한 논문으로 잘 알려진 Radford et al., (2019) 에서 확인할 수 있다. 하지만 InstructGPT에서 사용한 Supervised fine-tuning과, GPT-1에서 사용한 Supervised fine-tuning의 방식 및 목적이 조금 다르다고 생각하는데 그 이유는 다음과 같다.
우선 GPT-1에서는 Supervised fine-tuning을 사용할 때 Unsupervised pre-training한 GPT-3의 downstream task로써, 문장을 classification하는 추가적인 linear layer를 학습시키는 것이 목표이다.
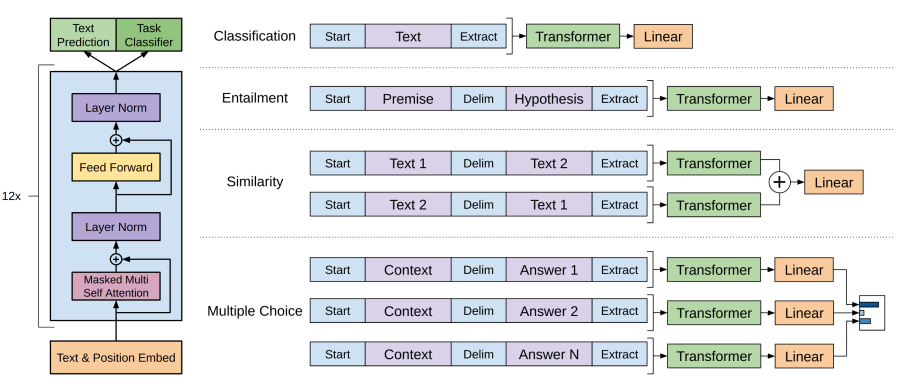
반면 InstructGPT에서 Supervised fine-tuning은 문장을 classification하는 목적이 아니므로, 추가적인 classification을 위한 linear layer 설정을 하지 않았을 것이며, 따라서 Supervised fine-tuning을 통해 GPT의 트랜스포머 레이어가 직접 학습하도록 하지 않았을까 생각한다. 그러므로 오히려 GPT-1의 Unsupervised pre-training에서 사용한 Next token prediction처럼, InstructGPT에서는 입력 문장 다음에 오는 출력 문장의 토큰만을 예측하는 식으로 학습이 진행되게 된다.
이를 수식으로 나타내면 다음과 같이 나타낼 수 있다.
Pθ(y|x)=m∏t=1Pθ(yt|y<t,x)
ˆθ=argmaxPθ(y|x)
여기서 x는 입력 문장, y는 출력 문장, θ는 모델의 학습가능한 파라미터를 각각 나타내며, y1,...,ym는 문장 y를 구성하는 토큰들이다. 즉 입력 문장에 대해 출력 문장이 나올 때, 이 출력 문장과 라벨러가 만든 이상적인 문장과의 유사도가 최대가 되게 하는 ˆθ를 찾는 것과 같은 문제가 된다.
예를 들어 아래와 같은 프롬프트 데이터가 있다고 치자.
입력 문장 : 여행지 세 곳 추천해줘
라벨러가 만든 이상적인 답변 문장 : 여행지에는 미국과 일본과 중국이 있습니다.
[여행지 세 곳 추천해줘]가 x가 될 것이고 [여행지에는 미국과 일본과 중국 등이 있습니다.]가 y가 되는데, y가 [여행지], [에는], [미국과], [일본과], [중국이], [있습니다.]로 토근화된다고 치면 각각 [y1],[y2],[y3],[y4],[y5],[y6]이 된다. (실제 모델에서는 WordPiece tokenizer를 이용해 훨씬 더 작은 단위로 토큰화가 이뤄진다.)
위의 식에 적용하게 되면 다음과 같다.
Pθ(y|x)=6∏t=1Pθ(yt|y<t,x)=Pθ(y1|x)×Pθ(y2|x,y1)×...×Pθ(y6|x,y1,...,y5)
여기서
Pθ(y1|x)×Pθ(y2|x,y1)×...×Pθ(y6|x,y1,...,y5)
은 출력 문장을 구성하는 각 토큰이 나올 확률을 차례대로 다 곱한 것이다.
이 확률 값이 최대가 되게 하는 파라미터 ˆθ를 찾는 식으로 학습을 진행한다.
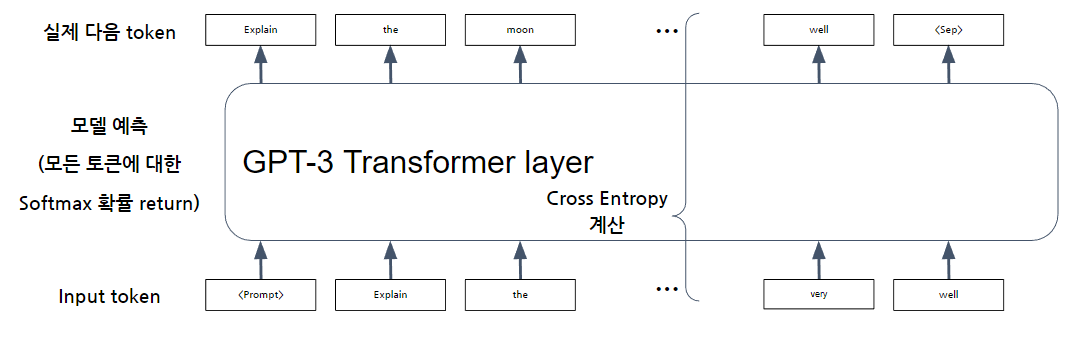
For stylistic continuation tasks we perform supervised fine-tuning of the language model to … prior to RL fine-tuning., Fine-Tuning Language Models from Human Preferences, Ziegler et al., (2020)
앞서 언급했듯이, 이러한 학습 방법을 통해 모델은 프롬프트 형식을 학습할 수 있으며, 또한 몇 가지 예시를 들어 질문한 것(few shot examples)에 답하는 방법을 학습할 수 있게 된다.
Step 2. Reward modeling (RM)
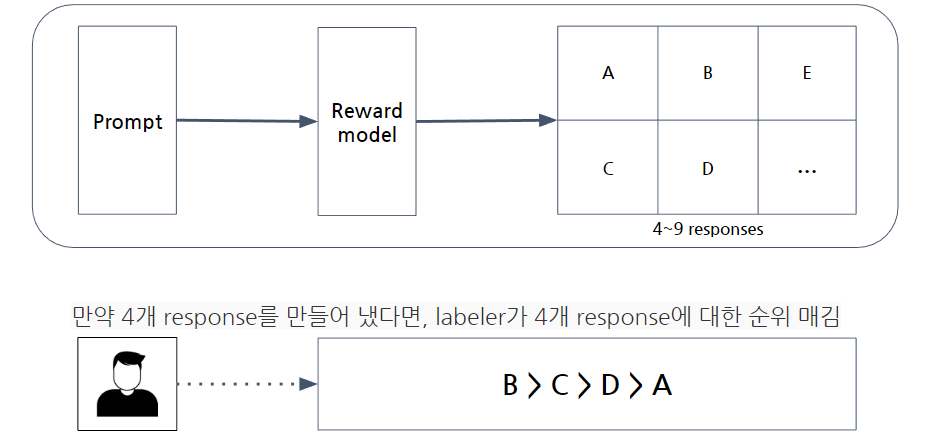
다음은 Reward model이다. Reward model은 전 단계에서 학습시킨 SFT 모델에서부터 시작한다. Reward model에서도 라벨러가 활용되는데, 라벨러들이 맡은 역할은 같은 모델이 반환하는 여러 출력 문장 간의 순위를 매기는 것이다. 논문에서는 한 입력 문장당 4개 ~ 9개의 출력 문장을 만들어내도록 하였다고 한다.
그 후에는 모델이 순위를 바탕으로 학습을 진행하게 되는데, 순위를 바탕으로 두 개씩 쌍으로 비교군을 만들고 각 비교군을 모두 활용해 모델을 업데이트 한다. 즉 비교를 한 번만 이용하는 것이 아닌 K \choose 2개를 뽑아 이용하게 된다.
예를 들어 4개의 출력 문장(= response)를 만들어 냈다면 다음과 같이 학습이 이루어진다.

업데이트 시 사용되는 손실 함수는 다음과 같다.
loss(\theta) = - {1 \over {k \choose 2}} E_{(x,y_w,y_l) \sim D} [log(\sigma (r_\theta (x,y_w) - r_\theta (x,y_l)))]
E는 기대값을, {(x,y_w,y_l) \sim D}는 x, y_w, y_l를 데이터 분포 D에서 추출다는 것을 의미하는데 이는 모델에 입력 문장 x가 들어가고 출력 문장으로 y_w, y_l가 나온 상황을 의미한다. 여기서 y_w는 비교한 두 출력 문장 중 라벨러가 더 선호하는 문장을, y_l는 덜 선호하는 문장을 나타낸다.
또 r_\theta (x,y_w), r_\theta (x,y_l)는 각각 입력 문장 x에 대해 y_w가 나왔을 때의 reward, y_l가 나왔을 때의 reward를 나타내는 것이며, r_\theta (x,y_w) - r_\theta (x,y_l)는 두 출력 문장의 reward 차이를 나타내는 것이다. (r_\theta (x,y_w), r_\theta (x,y_l)에 파라미터를 나타내는 \theta가 붙어 있으므로 이 손실 함수를 통해 reward model을 지속적으로 학습시키는 것을 알 수 있다.)
\sigma는 sigmoid 함수를 나타내는데, reward가 scalar 값이기 때문에 reward의 차이는 스칼라 값이 되고 이 값이 sigmoid 함수를 통과하게 되면 0에서 1사이의 값이 되며 log 함수를 통과하면 -\infty 에서 0 사이의 값이 나오게 된다.
reward 차이를 최대화하고 싶은데 손실 함수는 최소화 되도록 학습이 진행되므로 앞에 -가 붙은 것이다.
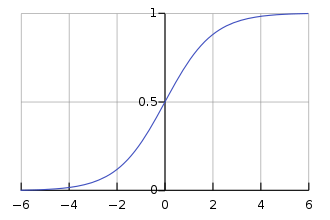
결국 이 손실 함수를 통해 더 선호하는 출력 문장에 대한 reward 값과 덜 선호하는 출력 문장에 대한 reward 값의 차이를 최대화하는 방향으로 학습이 진행되는 것이다.
다음과 같은 방법으로 학습이 끝난 Reward model은 인간의 선호를 잘 반영하는 모델이 된다. 제 이 모델을 강화 학습에 사용할 것이다. 강화 학습은 간단히 말해 reward를 최대화하는 방향으로 학습을 진행하는데, 앞서 학습시킨 Reward model이 인간의 선호를 잘 반영하도록 학습되었으므로, 강화 학습 역시 인간의 선호를 잘 반영하는 쪽으로 학습이 된다.
Step 3. Reinforcement learning (RL)
InstructGPT에서 사용된 강화학습은 Proximal policy optimization(PPO) 이다. 이 글에서 강화 학습에 대해 자세히 다루지는 않을 것이고 왜 PPO를 사용했는 지, 또 어떤 식으로 학습이 진행되는 지에 대해서만 다룰 것이다.
PPO는 2017년 OpenAI에서 발표한 강화 학습 알고리즘이다(Schulman et al., 2017). InstructGPT는 2022년에 발표되었으므로 PPO가 아닌 더 최신의 강화 학습 방법을 사용할 수도 있지만, PPO를 사용한 이유는 다른 최신 강화 학습 방법에 비해 구현이 간편하고 여러 상황에 적용하기 용이하다는 점 때문이 아닐까 추측할 수 있다.
InstructGPT의 각 요소를 강화 학습 요소에 대응시켜 보면 다음과 같다.
Agent : 학습을 받는 주체 -> PPO 모델
Environment : 학습 하는 상황 -> 입력 문장
Action : Environment에 대한 행동 -> 출력 문장
Reward : Action을 고려해 Agent에게 주는 보상 -> Reward model
Policy : Reward를 고려해 앞으로 어떻게 Action을 할 지 정하는 주체 -> PPO 모델 파라미터
여기서 Reward model은 앞선 Step 2를 통해 학습이 완료된 상태이고 더 이상 학습이 이뤄지지 않는 모델이다.
'The environment is a bandit environment which presents a random customer prompt and expects a response to the prompt.'
논문에서 언급한 것처럼 InstructGPT에 적용된 강화 학습은 밴딧(슬롯머신) 알고리즘과 비슷하다. 보편적으로 사용되는 강화 학습 알고리즘에서는 시간 지연에 대한 개념이 reward에 적용되는데(Delayed Reward), 밴딧 알고리즘과 InstructGPT 모두 시간 지연 개념이 적용되지는 않기 때문이다.
밴딧 알고리즘에서 여러 슬롯머신 중 하나를 고르는 것은 InstructGPT에서 입력 문장을 어떤 것으로 할 지 고르는 것과 유사하고, 슬롯머신 내에서 어떤 손잡이(Arm)을 당기면 보상이 최대화 될 지 최적화 하는 것은 출력 문장으로 어떤 문장을 내야 이상적인 문장과 유사해질 지 최적화 하는 것과 유사하다.
InstructGPT에서 강화 학습의 전체 과정을 도식화하면 다음과 같다.
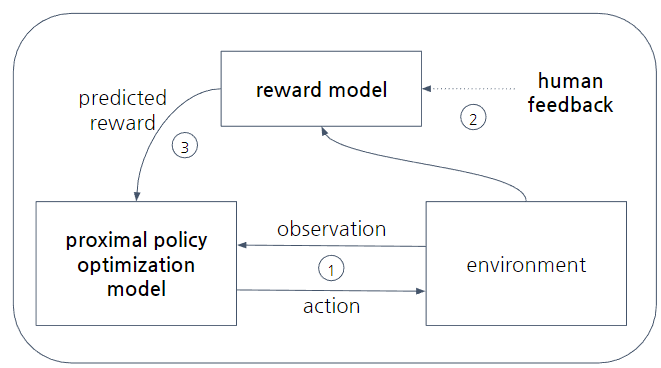
PPO는 여러 강화 학습 방법 중 policy 자체를 optimization 시키는 policy-based의 방법론이다. 그 중에서도 'proximal'이라는 말이 앞에 붙었는데, 'proximal'은 '근위의, 가장 근처의' 라는 뜻을 가지고 있다. 즉 PPO는 policy update를 통해 optimization 할 때 policy가 적당히 변할 때만 update 한다는 느낌으로 이해할 수 있다.
실제로 논문에 나온 PPO의 목적 함수를 살펴보면 다음과 같다.
(정확히는 PPO-ptx인데 이 차이는 뒤에서 서술할 예정이다.)
objective (\phi) = E_{(x,y) \sim D_{\pi_\phi^{RL}}}[r_\theta(x,y) - \beta log(\pi_\phi^{RL}(y \mid x)/\pi^{SFT}(y \mid x))] + \gamma E_{x \sim D_{pretrain}} [log(\pi^{RL}_\phi (x))]
각 항목을 하나씩 분리해 살펴보겠다.
우선 objective (\phi)은 \phi가 파라미터인 목적 함수를 의미한다. 즉 \phi가 들어간 항들은 다 이 목적 함수를 통해 학습된다.
다음으로
E_{(x,y) \sim D_{\pi_\phi^{RL}}}[r_\theta(x,y) - \beta log(\pi_\phi^{RL}(y \mid x)/\pi^{SFT}(y \mid x))]에서
E_{(x,y) \sim D_{\pi_\phi^{RL}}}는 학습 가능한 파라미터 \phi를 가진 강화 학습 모델에 x라는 입력 문장을 넣었을 때 출력 문장 y가 나온 상황이고, 그 때의 기대값을 의미한다.
또 r_\theta(x,y)은 Step 2에서 학습된 Reward model이다. 파라미터가 \theta이므로 이 목적 함수로 학습되지 않는 것을 알 수 있다.
- \beta log(\pi_\phi^{RL}(y \mid x)/\pi^{SFT}(y \mid x)) 이 항은 앞서 말한 policy가 적당히 변할 때만 update를 할 수 있도록 제약을 가하는 항이다.
\beta는 하이퍼 파라미터이고 \pi_\phi^{RL}(y \mid x)/\pi^{SFT}(y \mid x)에서
\pi_\phi^{RL}(y \mid x)은 학습 가능한 파라미터 \phi를 가진 강화 학습 모델에 x라는 입력 문장을 넣었을 때 출력 문장 y가 나올 확률을,
\pi^{SFT}(y \mid x)은 SFT 모델에 x라는 입력 문장을 넣었을 때 출력 문장 y가 나올 확률을 의미한다.
두 확률 값이 각각 분자와 분모에 있다. 논문에서는 \pi_\phi^{RL}(y \mid x)/\pi^{SFT}(y \mid x) 값이 0.8 에서 1.2 사이일 때만 학습이 되도록 하였다.
이와 같은 방법은 강화 학습으로 학습한 결과가 SFT의 결과와 너무 차이나는 것을 방지하는 역할을 한다. 논문에서는 다음과 같이 목적 함수를 설정한 모델을 'PPO' 모델이라 정의한다.
objective (\phi) = E_{(x,y) \sim D_{\pi_\phi^{RL}}}[r_\theta(x,y) - \beta log(\pi_\phi^{RL}(y \mid x)/\pi^{SFT}(y \mid x))]
그리고 PPO의 성능을 더 향상시키기 위해 기존의 목적 함수에 항을 하나 더 추가한 목적 함수를 가지는 모델을 'PPO-ptx'라 정의했다.
objective (\phi) = E_{(x,y) \sim D_{\pi_\phi^{RL}}}[r_\theta(x,y) - \beta log(\pi_\phi^{RL}(y \mid x)/\pi^{SFT}(y \mid x))] + \gamma E_{x \sim D_{pretrain}} [log(\pi^{RL}_\phi (x))]
We also experiment with mixing the pretraining gradients into the PPO gradients, in order to fix the performance regressions on public NLP datasets. We call these models “PPO-ptx.”
PPO-ptx에서 추가된 항 \gamma E_{x \sim D_{pretrain}} [log(\pi^{RL}_\phi (x))]의 역할은 강화 학습 모델과 Supervised fine-tuning 모델을 이용해 학습하기 전의 pretraining 데이터 분포를 기억할 수 있게 하는 것이다. 논문에서 밝히길 PPO 모델을 사용하니 특정 task에서 성능이 감소하는 performance regression이 심하게 일어나 이 항을 추가한 것이다.
\gamma는 하이퍼 파라미터이고 x \sim D_{pretrain}은 pretraining 데이터 분포에서 입력 문장 x를 추출한 것이다. 또 \pi^{RL}_\phi (x)은 강화 학습 모델에서 x가 나올 확률이다.
즉 기존의 PPO를 이용해 강화 학습을 진행하면서 pre-training의 데이터 분포를 너무 잊어버리는 문제로 인해 performance regression 문제가 발생했고 이를 해결하기 위해 pretraining 분포의 데이터를 강화 학습에 넣어 나온 확률을 규제 항으로 사용한 모델이 'PPO-ptx'이다.
이로써 본 논문에서 사용된 모델을 모두 알아보았다.
논문에서는 PPO-ptx를 InstructGPT라 명명하였는데, 성능 비교로는 SFT, PPO, PPO-ptx를 모두 사용하였다.
3. Results
논문에서는 모델을 평가할 때, 그 모델이 얼마나 'aligned' 되었는 지를 위주로 보았다고 서술한다. 총 세 가지로 aligned를 정의하는데, (1) helpful / (2) honest / (3) harmless이 그것이다.
(1) helpful
helpful을 판단하는 기준 자체가 명확하지 않고 모호하기 때문에, 논문에서는 helpful을 평가할 때 라벨러들의 판단에 의존했다고 밝히고 있다.
라벨러들이 평가한 결과는 다음과 같다.
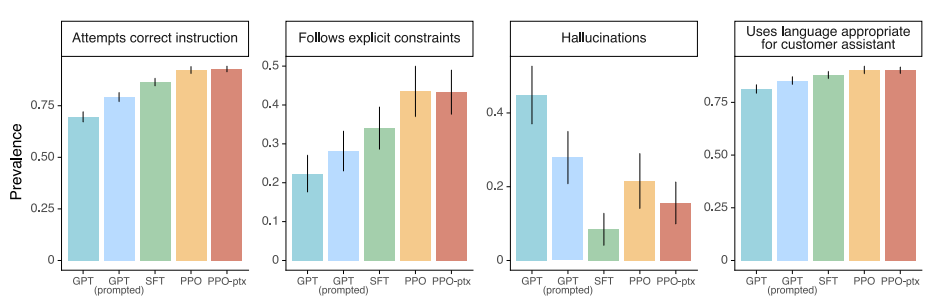
여기서 GPT는 GPT-3 모델을 의미하고 GPT(prompted)는 GPT-3 모델에 few-shot 예시를 준 prompt를 입력으로 사용한 모델을 의미한다.
결과적으로 대부분의 평가 항목에서 PPO, PPO-ptx 모델이 다른 모델보다 더 많은 선호를 받았다. 다만 Hallucination의 경우에는 SFT가 PPO, PPO-ptx 모델보다 더 낮은 Hallucinations를 생성한다고 평가 받았다.
(2) honest
helpful과 마찬가지로, honest 자체를 측정하는 것도 기준이 모호하고, 모델 자체가 'big black box'이므로 모델의 추론 결과가 honest 한지 그렇지 않은지 판단하기 어렵다고 밝히고 있다. 따라서 truthfulness를 대신 측정했다고 한다.
public NLP datasets 중 하나인 TruthfulQA dataset을 이용해 평가한 결과는 다음과 같다.
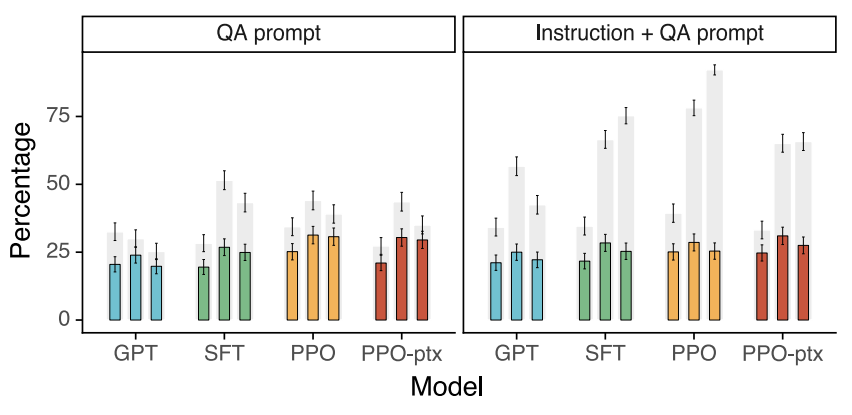
각 모델마다 그래프가 세 개 있는 것은 1.3B / 6B / 175B의 세 가지 크기를 가지는 모델을 각각 만들었기 때문이다. QA prompt는 질문(Question)과 그 질문에 대한 대답을 생성해야 하는 데이터 셋으로 평가한 것을 의미한다. 추가로 Instruction + QA prompt는 모델이 만약 정확한 답을 모를 경우 'I have no comment'라 답변할 수 있도록 지시를 추가한 프롬프트를 이용해 평가한 것을 의미한다. 여기서 회색 막대는 truthfulness만 나타내고, 색깔 막대는 truthfulness와 informativeness를 모두 나타낸다.
결과적으로 helpful에서 라벨러가 평가한 것과 유사하게 TruthfulQA dataset에서도 PPO, PPO-ptx 모델이 좋은 성능을 낸다는 것을 알 수 있다.
(3) harmless
harmless 역시 단순히 측정하기 어렵다고 논문에서 제시한다. 그 이유는 모델의 출력 문장이 실제 세상에서 어떻게 사용되는냐에 따라 해로움의 정도가 달라질 수 있기 때문이다. 어떤 상황에서는 해롭다고 판단된 출력 문장이 다른 상황에서는 해롭지 않다고 여겨질 수도 있다.
프로젝트 초기에는 출력 문장에 잠재적으로 해로울 수 있는지에 대해 라벨러가 평가 했으나, 이러한 평가는 라벨러의 추측이 너무 많이 필요했기에 중단하였다고 논문에서 밝히고 있다.
대신 public NLP datasets인 RealToxicityPrompts, CrowS-Pairs을 이용해 평가했다고 한다.
다음은 RealToxicityPrompts를 이용해 평가한 결과이다.
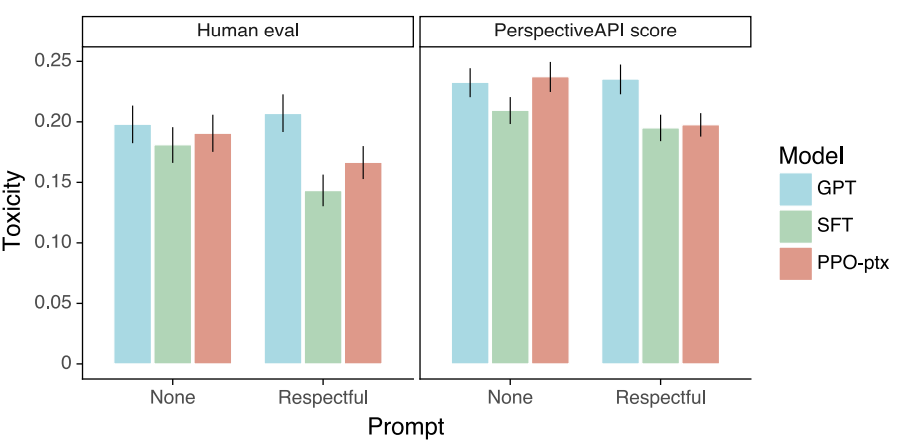
GPT, SFT, PPO-ptx 세 모델에 대해 평가했는데, 다양한 평가 방식에서 공통적으로 SFT가 제일 toxicity가 적은 것으로 나타났다. 또 GPT와 PPO-ptx를 비교했을 때 toxicity가 감소하는 경향은 있으나 그 폭이 크지 않다고 밝히고 있다.
논문에서는 toxicity와 더불어 bias에 관해서도 평가를 했는데, GPT와 PPO-ptx가 유사한 bias를 가지며 심지어 특정 상황에서는 PPO-ptx가 GPT 모델보다 더 높은 bias를 가진다고 밝혔다.
이때까지의 내용을 바탕으로 논문에서 내린 결론은 다음과 같다.
- RLHF를 이용하면 적은 파라미터를 이용해 기존의 모델보다 더 좋은 성능을 낼 수 있다.
- RLHF를 이용하면 public NLP datasets에서의 performance regression을 해결할 수 있다.
- InstructGPT는 fine-tuning할 때 사용하지 않은 instruction(한국어로 된 질문, 코딩 언어에 관한 질문 등)에 대해서도 다른 모델보다 더 좋은 성능을 낸다.
- InstrugtGPT는 여전히 개선 사항이 존재한다. (hallucination 문제, bias 증가 문제 등)
지금까지 InstructGPT를 제시한 Training language models to follow instructions with human feedback 논문에 대해 알아보았다. 본 글에서 언급한 내용 외에도 논문에서는 다양한 실험 환경, 결과 및 추가적인 내용을 상세히 서술하고 있으니 여건이 된다면 논문을 읽어보길 권장한다.
'Natural Language Processing' 카테고리의 다른 글
| [논문 리뷰] COT: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (0) | 2023.07.26 |
|---|---|
| [논문 리뷰] PromptBERT: Improving BERT Sentence Embeddings with Prompts (0) | 2023.07.13 |
| [논문 리뷰] LoRA: Low-Rank Adaptaion of Large Language Models (0) | 2023.06.18 |
| [논문 리뷰] LIMA: Less Is More for Alignment (2) | 2023.05.23 |