
이 글에서는 2023년 5월 18일 발표된 논문인 LIMA: Less Is More for Alignment에 대해 간략히 살펴볼 예정이다.
본 논문은 LLaMa 논문을 발표한 Meta AI로부터 발표되었으며 현재는 arxiv에만 올라온 상태이다.
논문 링크: https://arxiv.org/abs/2305.11206
LIMA: Less Is More for Alignment
Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We
arxiv.org
1. Introduction
(1) 현재 LLM은 라벨이 없는 대규모 말뭉치 코퍼스를 이용해 사전 학습을 진행한 뒤, 사람이 라벨링한 데이터를 활용해 파인 튜닝 하는 방식(RLHF)으로 학습을 진행시켜 왔다.
(2) 그러나 이런 방식에는 수백만 이상의 사람이 라벨링한 데이터가 필요하고, 엄청난 컴퓨팅 연산이 필요하다는 문제점이 있다.
(3) 본 연구에서는 잘 사전 학습된 모델에, 1000개만의 엄선된 라벨링된 데이터로 파인 튜닝을 한다면 좋은 성능을 낼 수 있음을 밝히고 있다.
(4) 1000개의 라벨링된 데이터는 다음과 같은 데이터를 포함한다.
- 750개의 질문과 답변 데이터 (Stack Exchange와 wikiHow에서 상위로 기록된)
- 250개의 연구자들이 직접 작성한 프롬프트와 응답 데이터
(5) 이 데이터를 활용해 65B LLaMa 모델을 사전학습 모델로 하고, 1000개의 데이터로 파인 튜닝시킨 LIMA 모델을 제시한다.
(6) 모델의 성능을 인간의 선호를 기준으로 살펴보면 다음과 같다.
- LIMA는 OpenAI의 RLHF가 적용된 DaVinci003보다 좋은 성능을 낸다.
- 똑같은 65B의 파라미터를 가지지만 52000개의 데이터로 학습시킨 Alpaca보다 좋은 성능을 낸다.
- 그러나 GPT-4, Claude, Bard와 비교했을 때는 성능이 뒤떨어진다.
(7) 본 연구는 또한 프롬프트의 다양성을 확장하지 않고 데이터의 수량만 확장시킬 때(= 데이터의 품질이 최적화되지 않을 때) 모델의 성능이 감소함을 드러낸다.
(8) 30개만의 사람이 만든 연속적인 대화 데이터가 LIMA의 연속적인 대화 성능을 매우 크게 끌어올렸다.
(9) 본 연구에 따르면 좋은 성능을 내는 데에 사전 학습은 절대적으로 중요하고, 대규모 프롬프트를 이용한 학습과 강화학습을 이용한 파인 튜닝은 데이터의 품질이 최적화된 경우에 효과적임을 밝히고 있다.
2. Alignment Data
(1) 본 연구에서는 다음과 같은 가설을 세운다.
- 모델의 대부분의 지식과 기능은 거의 사전 학습 중에 학습되고, 파인 튜닝을 통한 'alignment'는 사용자와 상호작용을 위해 필요한 기능을 학습할 뿐이다.
(2) 파인 튜닝을 통한 'alignment'가 단순히 모델이 사용자와 상호작용하기 위한 스타일을 학습하는 것이라면 위 가설의 결론은 작은 파인 튜닝 데이터셋으로도 사전 학습 모델을 충분히 학습시킬 수 있다는 것이다.
(3) 결론적으로, 본 연구에서는 1000개의 프롬프트/답변 쌍을 데이터셋으로 사용했으며, output은 형식적으로 유사하나 input(프롬프트)은 다양한 주제를 다룰 수 있도록 구성하였다.
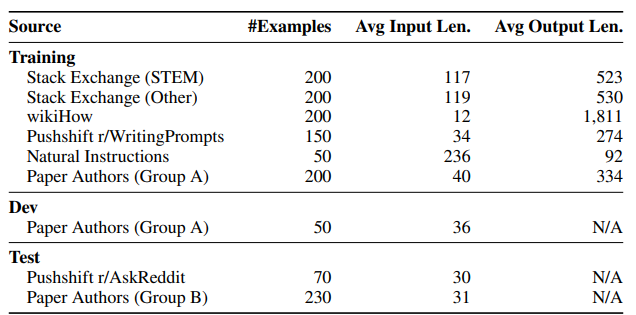
(4) 위 표는 학습 데이터셋 1000개, developmet 데이터셋(valid dataset처럼 학습에 참여하지 않고 모델의 성능을 일반화하고 조정하기 위해 사용되는 데이터셋) 50개, 그리고 테스트 데이터셋 300개에 대해 나타내고 있다.
2.1 Community Questions & Answers
(5) 본 연구에 사용된 데이터는 Stack Exchange, wikiHow, Pushshift Reddit Dataset에서 수집하였다.
(6) Stack Exchange, wikiHow의 답변은 상당히 'aligned' 되어 있기에 그대로 모델에 넣었지만, Reddit에서 수집된 답변들은 유머만 있거나 도움이 되지 않는 답변도 있기에 적절한 답변만 정제하여 모델에 넣었다.
(7) Stack Exchange
- 적절한 데이터를 추출하기 위해 다음과 같은 작업을 거쳤다. 우선 너무 짧거나 너무 긴 글을 필터링하고, 1인칭으로 쓴 글들을 필터링하였다. 그 후 다른 답변을 참조한 답변도 필터링했으며 답변 내에 링크, 이미지 등이 있으면 제거해 주었다.
(8) wikiHow
- 다양한 분야의 정보를 담기 위해 분야별로 질문/답변 데이터를 수집하였다. 또 글에서 "이 글은..." 으로 시작하는 내용이 있으면 "질문에 대한 답변은 ..."의 형식으로 문장을 전처리하였다.
(9) The Pushshift Reddit Dataset
- r/AskReddit, r/WritingPrompts 두 개의 카테고리에서만 데이터를 수집하였다. r/AskReddit에 수집된 데이터는 테스트 데이터셋으로 사용하였다. 또 r/WritingPrompts에는 Reddit 유저들이 소설을 창작하며 글을 적는 곳인데 여기서 수집된 데이터 150개는 트레이닝 데이터셋으로 사용되었다.
2.2 Manually Authored Examples
(10) 데이터의 다양화를 위해, 온라인에서 수집된 데이터셋 외에 본 연구를 하며 직접 제작한 프롬프트도 학습에 사용하였다.
(11) 그룹 A, 그룹 B에 해당하는 두 작가 그룹을 만들고, 각각 250개의 프롬프트를 만들게 하였다.
- 그룹 A의 프롬프트는 200개를 트레이닝 데이터로, 50개를 development 데이터로 사용하였다.
- 그룹 B가 만든 프롬프트 중 몇 가지 문제가 될만한 프롬프트를 제거한 뒤 230개의 프롬프트를 테스트 데이터로 사용하였다.
(12) 데이터의 다양성을 더욱 늘리고 모델의 견고함을 높이기 위해서, 직접 제작한 데이터 외에 Super-Natural Instructions(Wang et al., 2022b)에 소개된 자연어 생성 방법을 통해 데이터 50개를 샘플링해 사용하였다.
(13) 균일한 스타일을 가지면서 높은 다양성을 프롬프트를 일일이 만드는 것은 힘들고 노동력이 많이 들어가는 일이다.
(14) 그렇기에 최근 일부 연구는 증류 기법과 같은 방법으로 방대한 양의 데이터를 생성해내며 질보다 양으로 최적화하고자 한다.
(15) 이번 연구에서는 이와 다르게 데이터를 사용하는 데 있어서 양보다 질, 즉 다양성과 품질을 늘렸을 때의 효과를 알아보고자 한다.
3. Training LIMA
(1) LLaMa 65B 사전 학습 모델로부터 학습을 시작한다. 그리고 1000개의 데이터셋을 이용해 이 모델을 파인 튜닝 한다.
(2) 본 연구에서는 end-of-turn token (EOT)라는 스페셜 토큰을 사용했다. EOT 스페셜 토큰은 기본적으로 기존의 end-of-sentence (EOS) 토큰과 같은 역할을 하지만, 사전 학습을 하면서 학습된 EOS 토큰이 학습을 방해하는 것을 방지한다.
(3) 하이퍼파라미터는 표준적인 파인 튜닝시 사용되는 방식으로 사용하였다.
- 총 15 epochs 학습 진행
- AdamW 사용 ($\beta_1 = 0.9$, $\beta_2 = 0.95$, weight decay = 0.1)
- warmup step 없이 초기 learning rate는 1e-5로 시작해 1e-6까지 감소시킴
- batch size : 32, max_seq_len : 2048
- residual dropout을 사용했는데 가장 아래 레이어는 $p_d = 0.0$으로 시작해 $p_d = 0.3$까지 증가시킴
(4) 본 연구에서 알아낸 것은 perplexity가 답변 생성의 질과 연관되어 있지 않다는 것이다. perplexity를 관찰하며 checkpoint를 저장하지 않고 developmet 데이터셋을 이용해 직접 평가해가며 5-10 epochs 사이에서 수동으로 모델을 선정했다.
4. Human Evaluation
(1) LIMA의 성능과 state-of-the-art language modele들과 성능을 비교해 보았을 때, OpenAI의 RLHF로 학습한 DaVinci003보다 성능이 좋았으며, 65B를 가지고 52000개의 데이터로 학습한 Alpaca 모델보다 성능이 좋았다. 또 종종 GPT-4와 유사하거나 그 이상의 성능을 내기도 했다.
(2) 파인 튜닝에서 상당히 적은 데이터로 학습시키는 것만으로도 충분하다는 결과를 냈고, 또 이것은 사전 학습의 중요성과 대용량의 프롬프트 데이터셋을 이용한 학습과 강화학습이 데이터가 질적으로 좋을 경우에만 유의미한 것을 알 수 있었다.
4.1 Experiment Setup
(3) 비교 대상은 다음과 같다.
- Alpaca 65B
- DaVinci003
- Bard
- Claude
- GPT-4
(4) 비교 결과는 다음과 같다.
- 300개의 테스트 데이터셋에 대한 사람의 선호도 평가

- 300개의 테스트 데이터셋에 대한 GPT-4의 선호도 평가

(5) 비교방식은 다음과 같다.
- Human preferences : 사람에게 두 모델에서 나온 답변을 보여준 뒤 어느 답변이 더 나은지 판단한다.
- GPT-4 : 똑같은 방식을 GPT-4가 사람 역할을 하여 수행한다.
(6) 위의 표에서 Tie가 나오는 상황은 다음과 같다. 예를 들어 답변 A, B가 있을 때 두 명이 평가를 내리는데 한 쪽은 A 답변을 선호하고, 한 쪽은 B를 선호하는 경우이다.
4.2 Results
(7) LIMA는 사람의 선호에 있어서 DaVinci003, Alpaca보다 더 좋은 평가를 받는다.
(8) Bard와의 비교 시에 LIMA보다 사람의 선호에 있어서 42% 높은 선호를 보이지만 반대로 말하면 58%로 동등하거나 비슷할 수 있다는 것이다.
(9) Claude와 GPT-4와의 비교 시에 일반적으로 LIMA보다 두 모델의 성능이 우수하지만, LIMA가 더 나은 응답을 생성하는 경우도 적지 않게 있었다. 특히 아이러니하게도 GPT-4가 평가한 상황에서도 GPT-4의 응답보다 LIMA의 응답을 더 선호하는 경우가 19% 있었다.
4.3 Analysis
(10) LIMA를 평가할 때 사용된 데이터는 실제로 LIMA가 학습할 때 수백만명의 실제 유저가 만든 프롬프트로 이미 학습이 되어 있을 수도 있는데, 이런 경우에는 제대로된 평가가 되지 않을 수 있다.
(11) 따라서 본 연구에서는 모델 성능 평가에 있어서 50개의 무작위 프롬프트를 수동으로 분석하여 절대적인 평가(absolute assessment)를 제공하였다.
(12) 여기서 말하는 'absolute assessment'란 모델이 생성한 응답에 대해 사람이 주관적으로 판단하는 것이 아닌 객관적으로 분석하여 모델의 성능을 평가하는 것을 말한다.
(13) 그 후 50개의 프롬프트에 대한 응답을 세 가지 라벨로 분류하였고, 그 결과는 다음과 같다.

(14) 50%의 응답은 excellent로 평가되었다. 50개 기준으로 본다면 6개(12%)를 제외한 응답에 있어서 나쁘지 않은 평가를 받았다고 볼 수 있다.
(15) 여기서 Fail, Pass, Excellent의 기준은 다음과 같다.
Fail, the response did not meet the requirements of the prompt
Pass, the response met the requirements of the prompt
Excellent, the model provided an excellent response to the prompt.
(16) 위의 평가에서 50개 중 43개는 학습시 사용된 데이터와 비슷한 형식이었기에, 학습시 사용된 데이터와 다른 형식을 가진 데이터에 대해서도 평가를 진행했다.
(17) 그 결과, 20% fail / 35% pass / 45% excellent 성능이 나왔다.
(18) 비록 50개의 작은 데이터에 대한 평가지만 이것은 LIMA가 학습에 사용되지 않은 형식의 데이터에 대해서도 좋은 성능을 낼 가능성이 있음을 나타낸다.
(19) 마지막으로 훈련 데이터에 있는 적은 수(13개)의 안전 관련 프롬프트로 학습한 결과 분석이다.
(20) 테스트 데이터에 30개의 잠재적으로 위험한 프롬프트에 대해 LIMA는 그 중 80%에 대해 안전하게 응답하는 것을 확인했다. (악의적인 프롬프트 10개에 대해서는 6개에 대해 안전하게 대답했다.)
5. Why is Less More? Ablations on Data Diversity, Quality, and Quantity
(1) 본 연구에 따르면 input 다양성을 높이는 것은 output의 질적인 향상을 높이는데 긍정적인 영향을 미치는 것을 확인할 수 있었다. 반면 단순히 input의 수를 늘리는 것은 그렇지 못했다.
(2) 다음은 Diversity / Quality / Quantity와 관련된 실험 내용과 그 결과에 대한 것이다.

(3) Diversity
- Diversity의 영향을 확인하기 위해 Stack Exchange data는 이질적인(heterogeneous) 프롬프트로, wikiHow data는 동질적인(homogeneous) 프롬프트로 생각하고 각각 학습을 진행했다.
- 즉 Diversity 측면에서 Stack Exchange data가 wikiHowdata보다 낫다고 본 것이다. (논문에서도 이 부분에 대해서는 비약이 있음을 인정하고 있다.)
- 각각 2000개의 데이터를 이용해 훈련 데이터로 학습을 진행한 후 비교하였다.
- Diversity의 영향은 위의 사진에서 wikiHow와 Filtered Stack Exchange를 비교하면 알 수 있다. Filtered Stack Exchange는 높은 quality를 가지지고 높은 diversity를 가진다. wikiHow는 높은 quality를 가지지만 낮은 diversity를 가진다.
(4) Quality
- Quality의 영향은 Stack Exchange data에 quality를 높이는 필터의 유무로 확인했다. Unfiltered와 Filtered로 나누어서 결과를 냈는데, Filtered는 높은 diversity를 가지는 동시에 높은 quality를 가진 데이터를 의미하고 Unfiltered는 높은 diversity를 가지지만 낮은 quality를 가진 데이터를 의미한다.
(5) Quantity
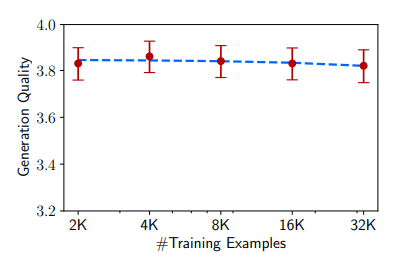
- (성능의 평가는 ChatGPT를 통해 이뤄졌다.)
- 데이터의 수를 늘리는 것은 모델의 성능을 높이는 데 효과적인 전략으로 알려져 있다.
- 그러나 본 연구에 의하면 데이터의 수를 두 배씩 늘려도 성능의 향상이 보이지 않았다.
(6) 이러한 결과에 비추어 볼 때, 양질의 응답을 생성하기 위해서는 단순히 quantity를 늘리는 것이 아닌 diversity를 늘리는 것이 중요하다는 것을 시사한다.
6. Multi-Turn Dialogue
(1) 우리는 실제로 1000개의 한 번 주고받은 데이터(single-turn interactions)로 여러 번 대화(multi-turn dialogue)를 주고받는 데 좋은 성능을 낼 수 있을까 생각했다.
(2) 따라서 우리는 LIMA를 10회 반복하는 대화를 하며 성능을 평가했다. (방식은 4.3처럼 Fail, Pass, Excellent를 이용)
(3) LIMA는 놀랍게도 이전 대화의 정보를 참고하는 zero-shot chatbot과 비슷한 성능을 냈다.
(4) LIMA가 훈련되지 않은 데이터에 대해서 잘 응답하는 것은 맞지만, 10개의 대화 중 6개의 대화에서 3회의 interaction 안에 프롬프트와 관련 없는 대답을 했다. (즉 아직 mulit-turn dialogue에 약하다고 볼 수 있다.)
(5) multi-turn 대화에서도 LIMA가 좋은 성능을 낼 수 있도록 새로운 데이터로 파인튜닝을 진행하였다.
(6) 30 multi-turn dialogue 데이터를 총 1030개 생성한 후, LLaMa를 파인 튜닝하여 새로운 버전의 LIMA를 만들었다. 그 후 zero-shot model과 성능을 비교하였고 아래는 그 결과에 대한 그림이다.

(7) 이 파인 튜닝을 통해 실패율이 35.7% (15 fails per 42 turns)에서 2.2% (1fail per 46 turns)로 감소하였다.
(8) 또 전체 대화의 quality를 추가로 비교했을 때, 파인 튜닝을 한 모델이 10개의 대화 중 7개에서 더 우수했으며, 3개의 모델은 동률(tie)였다는 것을 발견했다.
(9) 단 30개의 데이터를 이용해 이런 성능 향상이 일어나고, zero-shot 모델은 지속적인 대화를 하기 어려운 것을 알 수 있다. 이러한 사실은 대화를 지속할 수 있는 능력이 사전 학습을 통해 학습되기는 하지만 제한된 감독(limited supervision)이 있어야 발현될 수 있다는 본 연구의 가설을 강화한다.
7. Discussion
(1) 본 연구는 잘 학습된 사전 학습 모델을 오로지 1000개의 엄선된 데이터로 학습시키는 것이 좋은 모델을 만들 수 있음을 보였다.
(2) 그러나 한계도 존재하는데 다음과 같다. 데이터를 엄선하는 과정이 매우 중요하지만 그 과정이 힘들기에 규모를 키우기(ex. 10000개의 엄선된 데이터)가 힘들다는 것이다.
(2) 둘재로 LIMA는 GPT-4와 같은 'product-grad' 모델만큼 강력하지는 않다. LIMA는 대부분 좋은 응답을 생성하지만 어쩌다 좋지 않은 데이터가 샘플링되어 들어가는 경우, 적대적 프롬프트를 사용하는 경우에 좋지 않은 응답을 내놓는 경우가 있기도 했다.
(3) 즉 이번 연구에서 증명한 것은 간단한 접근 방식으로 복잡한 alignment 문제를 해결할 수 있는 잠재력을 보여준 것이다.