
이 글에서는 PromptBERT를 제안한 논문인 Improving BERT Sentence Embeddings with Prompts에 대해 간략히 살펴볼 것이다.
본 논문은 2022년 EMNLP에 발표되었으며 논문 링크는 다음과 같다.
논문 링크: https://arxiv.org/abs/2201.04337
PromptBERT: Improving BERT Sentence Embeddings with Prompts
We propose PromptBERT, a novel contrastive learning method for learning better sentence representation. We firstly analyze the drawback of current sentence embedding from original BERT and find that it is mainly due to the static token embedding bias and i
arxiv.org
0. Abstract
(1) 본 논문에서 말하고자 하는 것은 새로운 방법의 Contrastive learning을 통해 LLM에서 Sentence representation 성능 개선이다.
(2) 현재 BERT 모델에서 sentence representation(embedding) 성능이 좋지 않은 이유로 두 가지를 뽑고 있다.
- static token embedding bias
- ineffective BERT layers
(3) 본 논문에서 제안하는 것은 세 가지이다.
- 프롬프트 기반의 sentence embedding 방법론
- represent sentence with prompt 방법론
- 양질의 sentence embedding을 만드는 프롬프트 자체를 찾는 방법론
(4) 더하여 unsupervised learning과 supervised learning의 차이를 줄일 수 있는 새로운 unsupervised learning 방식을 제안하는데, 'template denoising'이 그것이다.
(5) unsupervised learning에서 본 연구에서와 유사하게 contrastive learning을 한 SimCSE와 비교해보면, BERT와 RoBERTa에서 각각 2.29, 2.58의 성능 향상을 이끌었다.
(6) 본 연구에서 사용한 코드는 https://github.com/kongds/Prompt-BERT에서 볼 수 있다.
1. Introduction
(1) 최근 pre-trained language model인 BERT와 RoBERTa가 Sentence embedding에서 좋은 성능을 내고 있다.
(2) 그러나 기존의 BERT가 sentence embedding에서 기존의 word embedding 방식인 GloVE를 이용한 방식과 비교했을 때 더 좋은 성능을 보여주지 못 하고 있다.
(3) 이전의 연구들은 기존의 BERT가 낮은 성능을 내는 것에 대해 anisotropy(비등방성)과 연관지어 설명하고 있다.
(4) 여기서 anisotropy(비등방성)란, 토큰의 임베딩이 좁은 콘 모양으로 분포하는 것을 말하며, 결과적으로 다른 문장들간의 임베딩 유사도를 높이는 원인이 된다.
(5) 그러나 본 연구의 결과에 따르면, anisotropy는 낮은 임베딩 성능의 주된 원인이 아니다.
(6) 예를 들어 BERT의 마지막 레이어를 평균 내어 sentence embedding을 구하는 것이 static token embedding을 이용해 sentence embedding 구하는 것보다 더 낮은 성능을 내는데(= 기존의 연구 결과에 따르면 BERT 임베딩이 더 anisotropy 해야 함), static token embedding을 이용한 쪽이 더 anisotropy했다고 밝혔다.
(7) 본 연구에서 주장하는 것은 기존 BERT의 레이어 자체가 sentence embedding의 질을 해친다는 것이다.
(8) 그렇다고 해서 BERT layer를 거치지 않은 static token embedding을 사용하는 것도 여전히 문제가 발생했다.
(9) 기존의 연구에서 토큰의 등장 빈도에 따라 임베딩에서 편향이 존재한다는 것이 밝혀졌는데, 본 연구에서는 토큰의 등장 빈도에 의해서만 영향을 받는 것이 아닌 WordPiece에서 subword에 의해서도 발생한다는 것을 밝혔다.
(10) 이를 증명하기 위해 단순히 빈도가 높은 subwords와 punctuation을 없애고 만든 단어의 평균을 문장의 임베딩으로 사용했는데 성능이 증가했으며, GloVe, BERT-flow, BERT-whitening보다 더 성능이 좋았다고 밝히고 있다.
(11) 즉, 임베딩 편향을 줄이는 것으로 sentence embedding 성능을 개선시킬 수 있다는 것을 알게 되었다.
(12) 그러나 임베딩 편향을 줄이기 위해 subwords와 punctuation를 일일이 골라 제거하는 것은 효율적이지 못하며, 짧은 문장에 적용할 경우 의미있는 단어 토큰이 사라질 수도 있다는 문제가 발생한다.
(13) 따라서 본 연구에서 임베딩 편향을 줄이기 위해 사용한 다른 방법은 BERT에 Prompt-based method를 적용하는 것이다. (GPT-3로부터 영감을 얻었다고 밝힘)
(14) 이는 문장 임베딩을 얻기 위해 특정 'Template'을 사용하는 것인데, 이를 통해 기존의 BERT기반 모델들보다 더 좋은 성능을 낼 수 있었다고 밝히고 있다.
(15) 또 파인 튜닝 상황에서 본 연구에서 제시한 방법을 사용하는 것이 기존의 방법들보다 더 나은 점을 언급하고 있는데, 구체적으론 다음과 같다.
- contrastive learning에서 unsupervised 방법론을 사용하면 positive pairs를 만드는 것이 어렵다는 문제가 있었다.
- 본 연구에서 제시하는 다른 형태의 Template을 이용해 positive pairs를 만들게되면 성능이 더 좋아진다고 주장하고 있다.
(16) 최종적으로, 'Template denoising' 기법을 사용한 프롬프트 기반의 contrastive learning 방법론을 제시하는데 unsupervised 상황과 supervised 상황에서 둘 다 SOTA를 달성할 수 있었다고 밝히고 있다.
2. Related Work
(1) 관련된 연구로는 먼저 SimCSE를 제시했다. 단순히 dropout으로 noise를 만든 뒤 positive pair로 활용하는 방식으로 contrastive learning 하는 방식이 문장 임베딩에서 좋은 성능을 보여주고 있다는 것이다.
(2) 기존의 버트가 문장 임베딩에서 좋은 성능을 못 내는데에 anisotropy로 인해 서로 다른 문장끼리 너무 높은 유사도를 가지기 때문이라 주장하는 연구들도 있다.
3. Rethinking the Sentence Embeddings of the Original BERT
(1) 기존의 연구들과 다르게 본 연구에서 주장하는 바는, anisotropy가 문장 임베딩 성능을 낮추는 주된 이유가 아니라 비효율적인 버트 레이어와 static 토큰 임베딩 편향이 주된 문제라는 것이다.
3-1. Observation 1: Original BERT layers fail to improve the performance.
(2) (버트 레이어를 통과하지 않은) static 토큰 임베딩과 버트 마지막 레이어의 토큰 임베딩 비교를 진행했다.
- 측정한 것은 문장 임베딩 성능 자체와 anisotropy 두 가지다.
- anisotropy를 측정하기 위해 Ethayarajh (2019)의 측정 방식을 이용하였다.
1n2−n|∑i∑j≠icos(M(si),M(sj))|
- M은 문장 임베딩 방식, cos는 코사인 유사도를 나타낸다.
- 만약 어떤 문장 임베딩 방식이 완전히 isotropic 하다면 평균적인 코사인 유사도가 0에 가까울 것이며, 반대로 anisotropic하다면 1에 가까울 것이다.
- 측정에 사용한 문장은 위키피디아 문장 코퍼스에서 랜덤으로 10만 개 문장을 샘플링하였다고 한다.
(3) 총 세 가지의 사전학습 모델 + 두 가지 문장 임베딩 방법, 6(3 * 2 = 6)가지의 결과는 다음과 같다.
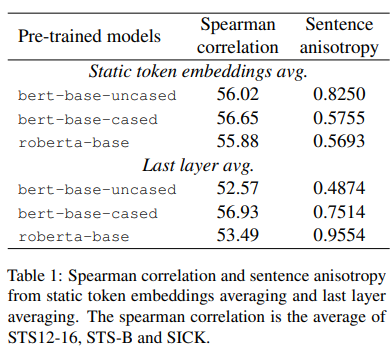
- 여기서 'uncased'는 대소문자 구분 없이 토큰화된 것이고 'cased'는 대소문자를 구분해 토큰화 한 모델을 나타낸다.
- 위 표에서 Spearman correlation 항목을 보면, 버트 레이어가 문장 임베딩 성능을 저하시킨다는 것을 알 수 있다.
- 또 주요하게 알 수 있는 점은 버트 레이어로 성능 감소는 있어도 문장의 anisotropy는 관련 없다는 것이다. (bert-base-uncased를 보면 Spearman correlation은 감소했지만 더 isotropy 해졌기 때문이다.)
3-2. Observation 2: Embedding biases harms the sentence embeddings performance
(4) 기존의 연구에 따르면 토큰의 빈도에 의해 토큰 임베딩의 편향이 발생할 수 있다는 것이 밝혀졌다.
- 여기서 임베딩 편향의 의미에 대해 간략히 설명하자면 토큰 임베딩의 분포가 토큰 빈도와 같이 관계없는 정보에 의해 방해받는 것이다.
(5) 실험 결과, 토큰 빈도에 의해서 편향이 발생할뿐만 아니라 WordPiece의 Subword에 의해서도 임베딩 편향이 발생한다고 논문에서 밝히고 있다.
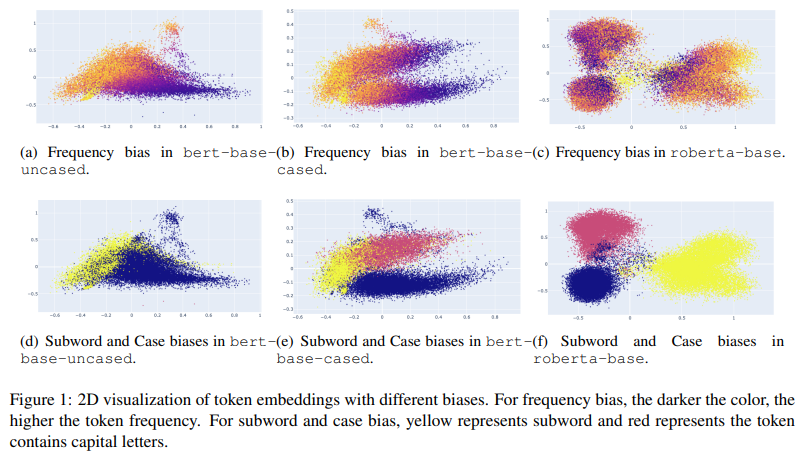
(6) 위 그림에서 편향을 시각적으로 보여주고 있는데 각각 다음과 같다.
- 남색 부분은 빈도가 높은 토큰들을 나타내는 것이다.
- 노란색 부분은 subword 토큰들을 나타내는 것이다.
- 빨간색 부분은 대분자 토큰들을 나타내는 것이다.
- 즉 토큰의 빈도 및 종류에 따라 임베딩 분포가 영향을 받는다는 것이다.
(7) 기존의 연구들은 anisotropy가 토큰 임베딩 편향의 주된 이유라고 주장하지만, 본 연구는 anisotropy는 편향과 관련없다고 주장한다.
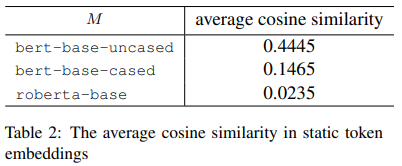
- 위 결과를 보면 bert-base-uncased에서만 평균 코사인 유사도가 높은데(높은 anisotropy), 이전 시각화 자료에서 본 것처럼 편향은 모든 모델에서 발생했기 때문이다.
(8) 결론적으로, 단순히 몇몇 토큰의 집합을 제거하는 것으로 문장 임베딩 성능이 증가하였다고 제시한다.
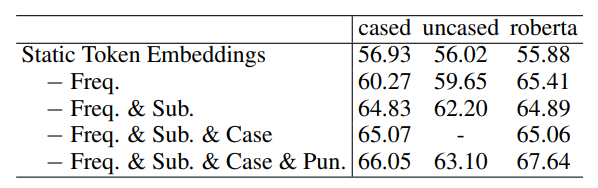
(9) 그러나 수동으로 특정 토큰을 제거하는 것은 성능을 높일 수는 있지만 너무 짧은 문장에 적용한다면 의미 있는 단어가 없어질 수도 있기 때문에 적절하지 않은 방식이라 논문에서 말하고 있다.
4. Prompt Based Sentence Embeddings
(1) 기존의 연구(Brown et al., 2020)에서 영감을 받아 프롬프트 기반의 문장 임베딩 생성 방법론을 본 논문에서 제시할 예정이다.
(2) 문장 임베딩을 얻는 것을 task를 Masked Language Model(MLM) task 방식을 이용할 것이며, [MASK] 토큰을 이용해 문장 임베딩을 represent 함으로써 임베딩 편향을 피하고자 했다고 논문에서 제시하고 있다.
(3) 그러나 text classification이나 question-answering task처럼 명확한 라벨이 없기에 어떻게 모델을 설계할 것인지 연구자들끼리 논의를 했고, 그 결과 프롬프트 기반의 contrastive learning을 활용해 버트를 파인 튜닝하고 문장 임베딩을 얻는 방법을 제시한다.
4.1 Represent Sentence with the Prompt
(4) 이 파트에서는 문장을 프롬프트 형식으로 represent하는 방법 두 가지에 대해 이야기할 것이다.
(5) 예를 들어 "[X] means [MASK]"같은 템플릿이 있다면 X에는 문장이 들어가고 MASK는 MASK 토큰을 나타낸다.
(6) 첫 번째 방법은 [MASK] 토큰 자체를 문장 representation으로 사용하는 것이다.
h=h[MASK]
(7) 두 번째 방법은 [MASK] 토큰을 vocab_size만큼 projection한 후 가장 확률이 높은 tok_k 토큰을 뽑아(MLM head) 그 토큰들을 가중 평균해 문장 representation으로 사용하는 것이다.
h=∑v∈Vtop−kWvP(v=[MASK]|h[MASK])∑v∈Vtop−kP(v=[MASK]|h[MASK])
- 여기서 Wv는 static token embeddings(버트 레이어를 거치지 않은 토큰 임베딩)을 나타내고 P 값은 MLM으로 얻은 토큰별 확률이다.
(8) 여기서 두 번째 방법은 조금 더 범용적이나 단점이 명확하다.
- static token embeddings를 평균내는 과정에서 편향의 문제가 발생한다.
- 가중 평균은 버트 모델에 down-stream task에서 파인 튜닝을 힘들게 한다.
(9) 따라서 본 연구에서는 문장 representation을 얻는데 첫 번째 방법을 사용할 것이라고 밝힌다.
4.2 Prompt Search
(10) 프롬프트 기반 task에서 가장 큰 문제는 프롬프트의 적절한 템플릿(template)을 찾는 것이다.
(11) 따라서 본 연구에서는 세 가지 방법으로 템플릿을 탐색하였다.
- 일일이 수동으로 찾기(manual)
- T5에 기초한 템플릿 생성(Gao et al., 2021a)
- OptiPrompt(Zhong et al., 2021)
(12) 연구진들이 좋을 것 같은 템플릿을 하나씩 만들어내 실험한 결과는 다음과 같다.(일일이 수동으로 찾기)
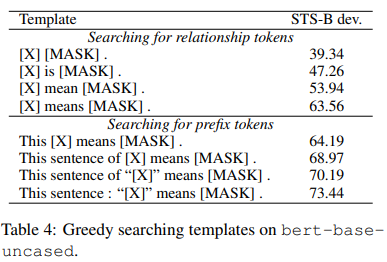
(13) T5 기반의 템플릿 생성은 라벨 토큰의 부족이라는 문제가 있다. (이 부분은 추가로 학습해 설명을 추가할 예정)
(14) 500개의 템플릿을 만들고 여러 시도를 해본 결과, “Also called [MASK]. [X]”가 64.75 정도의 점수를 얻었지만 수동으로 찾은 것보다 성능이 좋지는 않았다.
(15) 마지막으로 OptiPrompt는 discrete template을 continuous template으로 바꾸는 것이다.
(16) continuous template을 최적화하기 위해 unsupervised contrastive learning을 진행하였다.
(17) 버트의 파라미터는 고정시키고 continuous template을 학습시키는데, 수동으로 찾은 템플릿의 static token embeddings를 초기값으로 설정하였다.
(18) 이 방식으로 수동으로 찾은 template 중 가장 좋은 점수인 73.44를 80.90까지 올릴 수 있었다.
4.3 Prompt Based Contrastive Learning with Template Denoising
(19) contrastive learning에서 다양한 방식으로 positive instance를 만드는 방법이 제시되었다.
(20) 본 연구에서 사용한 방식은 다음과 같다.
- 서로 다른 템플릿을 사용하여 다른 관점에서 바라본 문장 임베딩을 얻는 것이다.
- 또 문장 임베딩에서 템플릿 자체의 영향을 줄이기 위해 템플릿 정보를 denoise했다.
(21) 주어진 문장 xi에 대해 템플릿을 이용해 문장 임베딩 hi를 뽑는다. 그 후 버트에 템플릿만 넣는데, 이를 통해 템플릿으로 인해 발생하는 편향 ^hi을 계산한다.
(22) hu−^hi을 사용해 템플릿 편향이 제거된(노이즈가 제거된) 문장 표현을 사용한다.
li=−logecos(hi−^hi,h′i−^h′i)/τ∑Nj=1ecos(hi−^hi,h′j−^h′j)/τ
- τ는 temperature 하이퍼 파라미터이고 N은 미니 배치의 크기이다.
5. Experiments
(1) 본 연구에서 제시한 방법론의 성능을 측정하기 위해 STS task를 이용하였다. (STS task는 Semantic Textual Similarity의 준말로서, 텍스트로 구성된 문장 사이의 유사도를 맞추는 task이다.)
5.1 Dataset
(2) STS task를 위해 7개 종류의 STS datasets를 이용하였다.
(3) 문장 쌍에 대해 유사도가 0~5점 사이 점수로 매겨져 있는 것을 맞추는 task이다.
5.2 Baselines
(4) 사용한 모델은 다음과 같다.
- GLoVe embedding avg. (단어 embedding인 GLoVe를 이용해 문장의 embedding을 각각 단어 embedding 값의 평균으로 구성하는 것)
- BERT sentence embedding
- BERT-flow
- BERT-whitening
- IS-BERT
- InferSent
- Universal Sentence Encoder
- SBERT
- SimCSE
- ConSERT
(5) 총 세 가지 방법으로 비교를 진행했는데, 다음과 같다.
- fine-tuning을 진행하지 않은 모델
- unsupervised fine-tuning을 진행한 모델
- supervised fine-tuning을 진행한 모델
5.3 Results
(6) fine-tuning을 진행하지 않은 모델
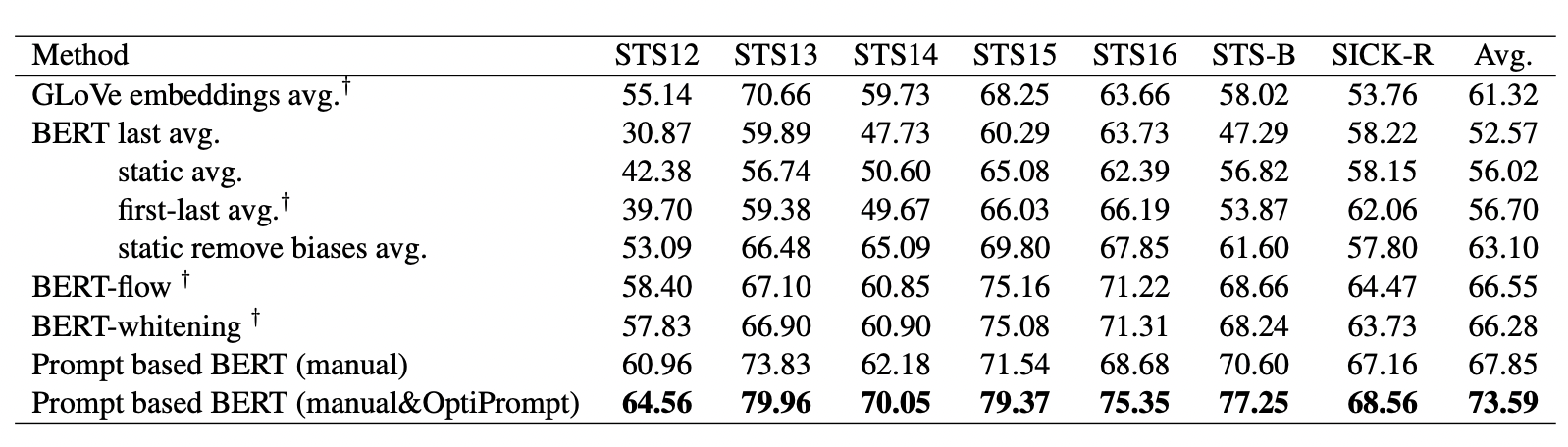
- Prompt를 이용한 BERT 모델이 거의 모든 task에서 가장 좋은 성능을 보여주고 있다.
(7) fine-tuning을 진행한 모델 (unsupervised & supervised)
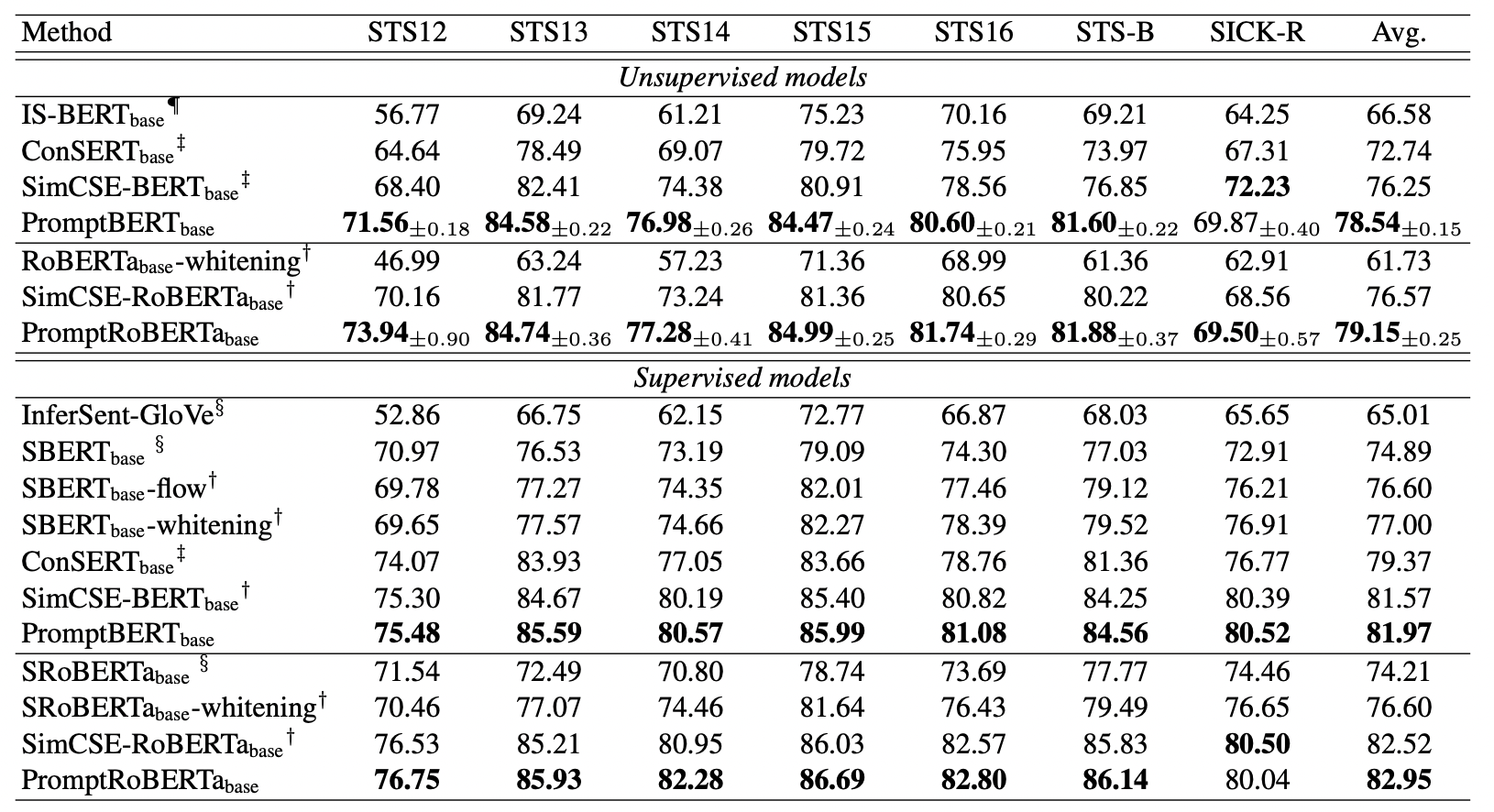
- 본 연구에서 사용한 방법인 Prompt를 사용한 contrastive learning은 다른 모델과 비교해서 가장 좋은 성능을 보여준다.
- 뿐만 아니라 unsupervised fine-tuning과 supervised fine-tuning의 성능 차이을 줄일 수도 있다.
- 기존의 가장 좋은 contrastive learning 방법 중 하나인 SimCSE보다 더 좋은 성능을 낼 뿐만 아니라, random seed를 바꿔 학습을 여러번 진행했을 때도 더 안정적인 성능을 보여준다.
5.4 Effectiveness of Template Denoising
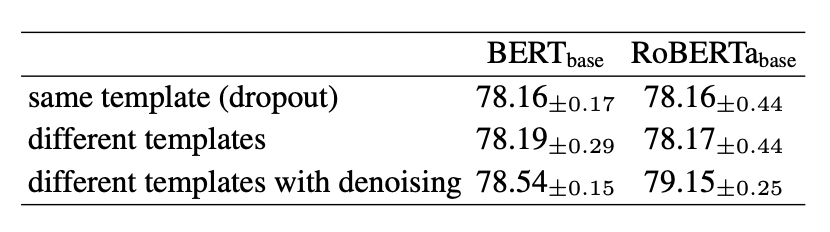
(8) 기존의 SimCSE에서는 같은 template에서 dropout 적용을 통해 noise를 추가하고 positive pair를 만들었다.
(9) 본 연구에서는 다른 prompt template을 사용한 방법과, 거기서 dropout 적용을 통해 noise를 추가한 방법(template denoising) 두가지를 이용해 각각 positive pair를 만들어 기존의 모델(SimCSE)과 성능 비교를 하였다.
(10) 그리고 아래는 template denoising을 사용한 모델에서 MLM head를 이용해 Top-5 token을 뽑은 결과이다.

- 확실히 template denoising을 사용한 결과가 문장의 맥락과 유사한 토큰을 잘 뽑는 것을 볼 수 있다.
6. Conclusion
(1) 본 논문에서는 기존 BERT 모델의 sentance embedding 성능이 낮은 이유를 분석하고, 이를 개선하고자 했다.
(2) prompt-based의 sentence embedding을 제시했으며 이를 통해 sentence embedding 성능을 높일 수 있었다.
(3) 또 template denosing을 활용한 contrastive learning을 적용해 더욱 성능을 높일 수 있었다.
(4) 본 연구에서 제시한 방법이 성능을 높일 수 있다는 것을 STS task에서의 성능 향상을 통해 증명했다.
7. Limitation
(1) prompt template을 이용한 모델이 좋은 성능을 내는 것은 맞지만, 본 연구에서 제일 좋은 성능을 내는 prompt template은 연구자들이 일일이 찾은(manually) 템플릿이었다.
(2) T5를 이용해 자동으로 생성하고자 했으나 성능이 좋지 않았기 때문이다.
(3) 따라서 본 연구진들은 future work로 더 좋은 성능을 내는 prompt template을 만드는 방법을 고안하는 것을 제시했으며, 이를 통해 성능을 더 높일 수 있고, 더 효율적일 것이라 언급한다.