ChatGPT와 강화학습
ChatGPT는 기존의 GPT-3를 고품질의 데이터로 fine-tune 시킨 뒤, RLHF(Reinforcement Learning from Human Feedback)를 시킨 것이다.
ChatGPT가 정확히 어떤 방식으로 학습 시켰는지에 대한 논문은 나와 있지 않으나 거의 유사한 방식으로 학습시켰다고 알려진 InstructGPT의 데이터셋 및 학습 방법에 대한 논문은 있기에, 이를 바탕으로 설명하고자 한다.
GPT-3와 InstructGPT가 생성하는 답변의 차이는 다음 예시를 보면 직관적으로 이해할 수 있다.

GPT-3가 생성시킨 Output을 보면 Input과 유사한 느낌은 있지만, 사용자가 원하는 Output은 아니다.
반면에 InstructGPT가 생성한 Output을 보면 사용자가 입력한 Input에 대해 비교적 사람이 원할 만한 대답을 하고 있는 것을 알 수 있다.
이런 Output 생성에서 차이를 낼 수 있었던 큰 요인 중 하나가 바로 RLHF이다.
Human Feedback을 이용한 강화학습을 통해 InstructGPT가 사용자들이 ‘원하는 대답’을 생성할 수 있도록 학습시킨 것이다.
(위의 그림에서는 Reward model과 reinforcement learning을 통해 Instruct GPT에 RLHF가 적용되었음을 알 수 있다.)
InstructGPT에 사용된 강화학습 방법은 PPO(Proximal Policy Optimization)이고, 위의 수식은 학습에 사용된 목적함수이다.
추후에 이 목적 함수에 대해서도 알아볼 것인데, 이 글에서는 InstructGPT에 사용된 PPO의 기본이 되는 기본적인 강화학습 방법부터 차근차근 접근해보려 한다.
Multi-Armed Bandit
Multi-Armed Bandit(이하 MAB) 알고리즘은 강화학습에서 가장 기초적인 알고리즘이다.
MAB의 원리는 간단하다. 슬롯머신에 당길 수 있는 레버(arm)가 여러 개 있고, 각 레버마다 보상을 획득할 확률이 다르다. 사용자는 각 레버의 보상 획득 확률을 모르는 상태에서 최대의 보상을 획득하기 위한 방법을 찾아가는 알고리즘이다.
전체 알고리즘은 다음과 같다.
# multi-armed bandit -> 하나의 bandit인데 여러 개의 arms
import numpy as np
import torch
import torch.optim as optim
class BanditEnvironment:
# 밴딧의 arm 개수 4개로 설정
def __init__(self, n_arms):
self.n_arms = n_arms
# self.arms는 arm마다 임의의 값을 지정해 줌. 이 값을 이용해 어느 arm을 당겨야 가장 큰 보상이 올 지 정할 예정
# 여기서 self.arms[3], 즉 네 번째 arm의 값이 가장 작다(-1)
# 즉, 랜덤한 값 임의추출 했을 때 그 값보다 arm의 값([0.2,0,-0.2,-2])이 작을 확률이 가장 높다.
# 네 번째 arm을 자주 당기면 보상이 최대화되는 것
self.arms = np.array([0.2,0,-0.2,-1])
def pull(self, arm):
# 0-1 사이의 랜덤한 값을 구한다
result = np.random.randn(1)
if result > self.arms[arm]:
return 1
else:
return -1
class SoftmaxPolicy:
def __init__(self, n_arms, temperature):
self.n_arms = n_arms
# temperature 값이 높을수록 무작위성이 커지고 안정되지 않은 선택을 할 확률이 강조됨
# temperature 값이 0에 가까워질수록 정책에 따른 선택이 거의 절대적으로 이루어짐
# 즉, 탐험(exploration)을 하지 않고 안정적인 선택(exploitation)을 더 많이 함
# 반대로 temperature 값이 커지면 탐험을 더 많이 함(log_softmax에서 각 weights의 확률 값 차이가 적어짐)
self.temperature = temperature
self.weights = torch.zeros(n_arms, requires_grad=True)
def __call__(self):
probs = torch.softmax(self.weights / self.temperature, dim=0)
return probs
def update(self, arm, reward, optimizer):
log_prob = torch.log_softmax(self.weights / self.temperature, dim=0)[arm]
loss = -log_prob * reward
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 밴딧 수, temperature 설정
n_arms = 4
temperature = 10
# Hyperparameters
n_episodes = 50
n_steps_per_episode = 1000
learning_rate = 0.01
# Initialize environment and policy
env = BanditEnvironment(n_arms)
policy = SoftmaxPolicy(n_arms, temperature)
# Define optimizer
optimizer = optim.SGD([policy.weights], lr=learning_rate)
# Training loop
for episode in range(n_episodes):
total_reward = np.zeros(n_arms)
for step in range(n_steps_per_episode):
# Choose arm according to policy
probs = policy()
# 다항분포에서 num_samples 개수의 표본을 생성
# .items()를 통해 Tensor 값을 int로 변환
# 액션 할 arm 번호 선택 (0-n_arms 중 하나의 값)
arm = torch.multinomial(probs, num_samples=1).item()
# Receive reward from environment
reward = env.pull(arm)
total_reward[arm] += reward
# Update policy
policy.update(arm, reward, optimizer)
# Print total reward for episode
print(f"Episode {episode+1}: Total reward = {total_reward}")
print("Testing policy...")
print(f"The agent(Policy) thinks action {np.argmax(total_reward) + 1} is the most promising....")
if np.argmax(total_reward) == np.argmin(env.arms):
print("...and it was right!")
else:
print("...and it was wrong!")
(Numpy와 Pytorch만 설치하면 CPU 환경에서도 코드를 실행할 수 있다.)
BanditEnvironment 클래스
class BanditEnvironment:
# 밴딧의 arm 개수 4개로 설정
def __init__(self, n_arms):
self.n_arms = n_arms
# self.arms는 arm마다 임의의 값을 지정해 줌. 이 값을 이용해 어느 arm을 당겨야 가장 큰 보상이 올 지 정할 예정
# 여기서 self.arms[3], 즉 네 번째 arm의 값이 가장 작다(-1)
# 즉, 랜덤한 값을 임의추출하여 비교할 때 그 값보다 arm의 값([0.2,0,-0.2,-2])이 작을 확률이 가장 높다.
# 네 번째 arm을 자주 당기면 보상이 최대화되는 것
self.arms = np.array([0.2,0,-0.2,-1])
def pull(self, arm):
# 0-1 사이의 랜덤한 값을 구한다
result = np.random.randn(1)
if result > self.arms[arm]:
return 1
else:
return -1
n_arms = 4
env = BanditEnvironment(n_arms)
현재 밴딧에 arm이 4개 있고 env.arms에는 [0.2,0,-0.2,-1] 값이 저장되어 있다. 이는 강화학습에서 Environment에 해당한다.
Environment는 후술할 Agent가 상호작용하여 학습하는 대상이 되는 것이다.
여기서 env.pull(arm) 이 결국 Agent로 볼 수 있다. Agent는 강화학습에서 행동하는 주체를 의미하는데, MAB 상황에서는 어떤 arm을 당길 지 선택하는 역할을 한다.
결론부터 말하자면 arms의 값이 작을 수록 보상을 획득할 확률이 높기 때문에, 위의 상황에서는 4번째 arm의 값이 -1로 가장 작고, 따라서 많이 당겨야 보상을 최대화할 수 있는 것이다.
SoftmaxPolicy 클래스
class SoftmaxPolicy:
def __init__(self, n_arms, temperature):
self.n_arms = n_arms
# temperature 값이 높을수록 무작위성이 커지고 안정되지 않은 선택을 할 확률이 강조됨
# temperature 값이 0에 가까워질수록 정책에 따른 선택이 거의 절대적으로 이루어짐
# 즉, 탐험(exploration)을 하지 않고 안정적인 선택(exploitation)을 더 많이 함
# 반대로 temperature 값이 커지면 탐험을 더 많이 함(log_softmax에서 각 weights의 확률 값 차이가 적어짐)
self.temperature = temperature
self.weights = torch.zeros(n_arms, requires_grad=True)
def __call__(self):
probs = torch.softmax(self.weights / self.temperature, dim=0)
return probs
def update(self, arm, reward, optimizer):
log_prob = torch.log_softmax(self.weights / self.temperature, dim=0)[arm]
loss = -log_prob * reward
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 밴딧 수, temperature 설정
n_arms = 4
temperature = 10
policy = SoftmaxPolicy(n_arms, temperature)
SoftmaxPolicy는 호출되었을 때 각각의 arm이 선택될 확률을 return한다.
이 확률에 영향을 미치는 것은
probs = torch.softmax(self.weights / self.temperature, dim=0)이 식에서 알 수 있듯 self.weights 와 self.temperature 이다.
weights는 학습이 되는 대상이고, temperature는 hyperparameter인데, 역할은 탐험(exploration)과 안정적인 선택(exploitation)을 얼마나 할 지 선택해주는 역할을 한다.
학습은 policy.update를 통해 진행된다.
loss function은
log_prob = torch.log_softmax(self.weights / self.temperature, dim=0)[arm]
loss = -log_prob * reward다음과 같이 정의되어 있으며 loss function을 최소화하는 방식으로 학습된다.
Training Loop
# 밴딧 수, temperature 설정
n_arms = 4
temperature = 10
# Hyperparameters
n_episodes = 50
n_steps_per_episode = 1000
learning_rate = 0.01
# Initialize environment and policy
env = BanditEnvironment(n_arms)
policy = SoftmaxPolicy(n_arms, temperature)
# Define optimizer
optimizer = optim.SGD([policy.weights], lr=learning_rate)
# Training loop
for episode in range(n_episodes):
total_reward = np.zeros(n_arms)
for step in range(n_steps_per_episode):
# Choose arm according to policy
probs = policy()
# 다항분포에서 num_samples 개수의 표본을 생성
# .items()를 통해 Tensor 값을 int로 변환
# 액션 할 arm 번호 선택 (0-n_arms 중 하나의 값)
arm = torch.multinomial(probs, num_samples=1).item()
# Receive reward from environment
reward = env.pull(arm)
total_reward[arm] += reward
# Update policy
policy.update(arm, reward, optimizer)
# Print total reward for episode
print(f"Episode {episode+1}: Total reward = {total_reward}")
전체적인 학습 과정은 다음과 같다.
각 episode(epoch에 해당)마다 1000번 pull하며, 총 episode는 50으로 설정했다.
학습의 결과는 다음과 같다.
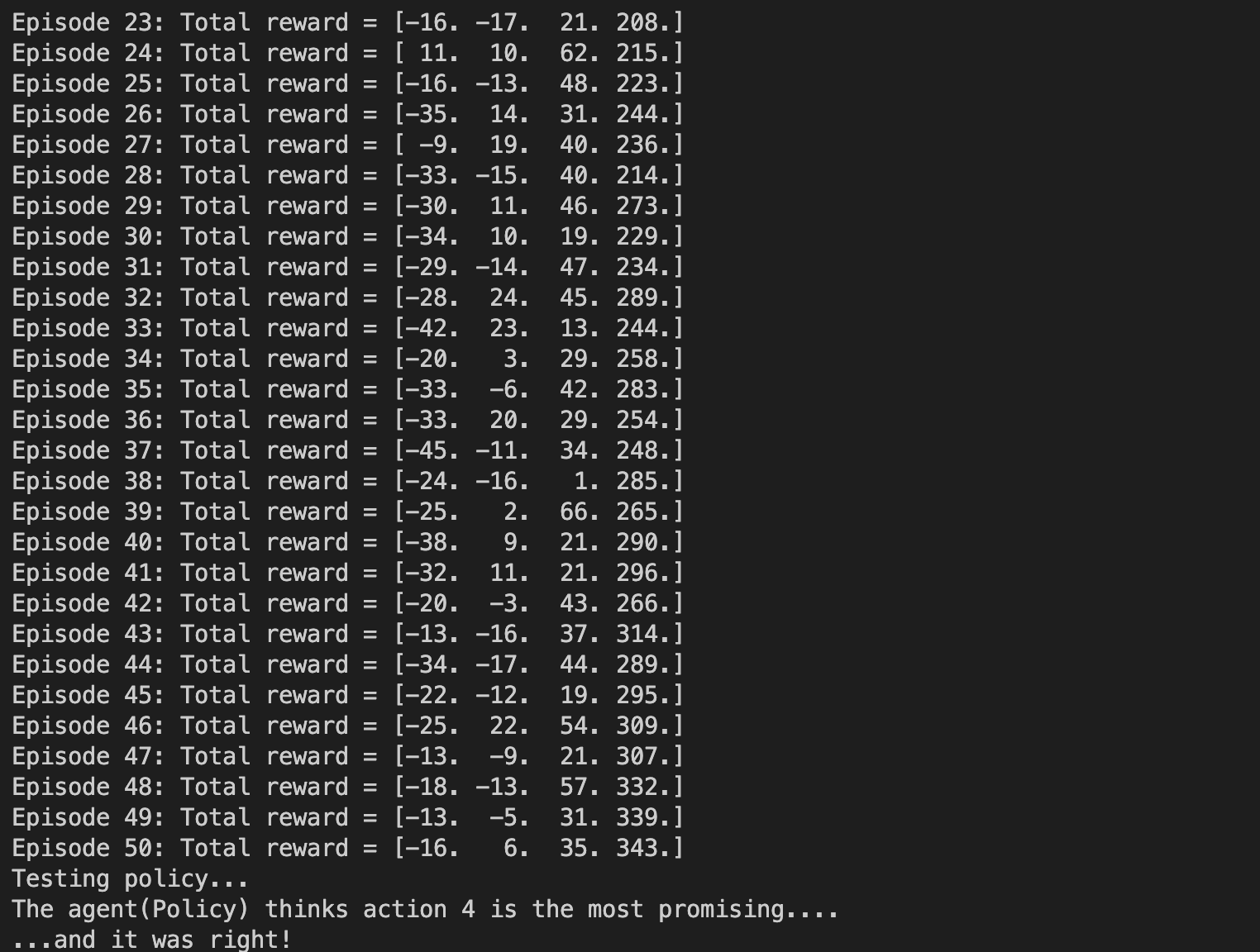
episode가 진행될 수록 4번 arm이 가장 많은 reward를 획득하고,
이는 4번 arm이 가장 많은 보상을 주는 쪽으로 학습이 진행되었다는 것을 의미한다.
따라서 잘 학습이 진행되었다고 볼 수 있다.
이번 글에서는 강화학습에 가장 기본이 되는 Multi-Armed Bandit에 대해 알아보았다.
다음 글에서는 Multi-Armed Bandit에서 State, Time 등 다른 요인들이 적용된 강화학습에 대해 다뤄보고자 한다.
'Reinforcement Learning' 카테고리의 다른 글
| 강화학습과 지도학습은 어떻게 다를까? (2) | 2023.04.11 |
|---|---|
| Banilla Policy Gradient를 Pytorch로 구현해 보자 (0) | 2023.04.09 |