(1) Medical Visual Question Answer: A Survey 논문은 2023년 Artificial Intelligence in Medicine 학회에 accept된 논문이다.
(2) 본 논문에서는 컴퓨터 비전 태스크 중 하나인 Visual Question Answering을 의료 분야에 적용한 Medical Visual Question Answering(Medical VQA)에 대해서 살펴보는데 데이터셋, 평가방법 및 방법론을 위주로 연구한 Survey 논문이다.
논문 링크: https://arxiv.org/abs/2111.10056
Medical Visual Question Answering: A Survey
Medical Visual Question Answering~(VQA) is a combination of medical artificial intelligence and popular VQA challenges. Given a medical image and a clinically relevant question in natural language, the medical VQA system is expected to predict a plausible
arxiv.org
0. Medical VQA 연구
(1) medical VQA 태스크는 인공지능 모델이 a.이미지와 b.이미지에 대한 질문 텍스트를 input으로 받고, 이미지와 텍스트 정보를 이용해 질문에 대한 답을 모델이 generate하는 태스크이다.
(2) 논문에서 밝히길, VQA 태스크에 대한 연구는 많이 있어 왔지만, medical 도메인에서의 VQA 태스크에 대한 연구를 많지 않았다고 밝히고 있다.
(3) 본 연구를 시작하며 medical VQA를 알기 위해 가장 먼저 살펴본 것은 현재까지 나온 medical VQA 데이터셋들을 살펴보았다.
(4) 그 이후에 medical VQA 태스크를 해결하기 위해 나온 여러 방법론에 대해 살펴보았다.
(5) 논문의 마지막에는 현재 이 태스크에서의 한계 및 발전 방향에 대해 논의하고자 한다.
1. medical VQA에 대한 이해
(1) VQA 태스크는 컴퓨터 비전과 자연어 처리가 결합한 태스크이다.
(2) medical VQA는 radiologist가 CT나 MRI 이미지를 해독하는 것을 도울 수 있으며, 영상의학과 전문의를 돕는 조력자 역할을 할 수 있다.
(3) 또한 medical VQA를 환자가 직접 이용한다면 병원을 방문한 뒤, 추가적인 정보를 환자가 온라인 상황에서도 찾아볼 수 있다.
(4) 그러나, medical VQA는 일반적인 VQA보다 훨씬 어려운 태스크이다. 기본적으로 큰 규모의 medical VQA 데이터셋을 만드는 것 자체가 어렵기 때문이다.
(5) 데이터셋을 만들기 위해 medical 도메인에 대한 전문적인 지식이 있어야하며, 의료 이미지에 대한 Question과 Answer을 구성할 때 이미지 정보를 정확하게 담는 QA를 구성하는 것도 어렵다.
(6) 첫 번째 medical VQA challenge는 2018년에 시작되었으며, 점점 더 그 규모와 연구자 수는 커졌다.
2. medcial VQA - 데이터셋
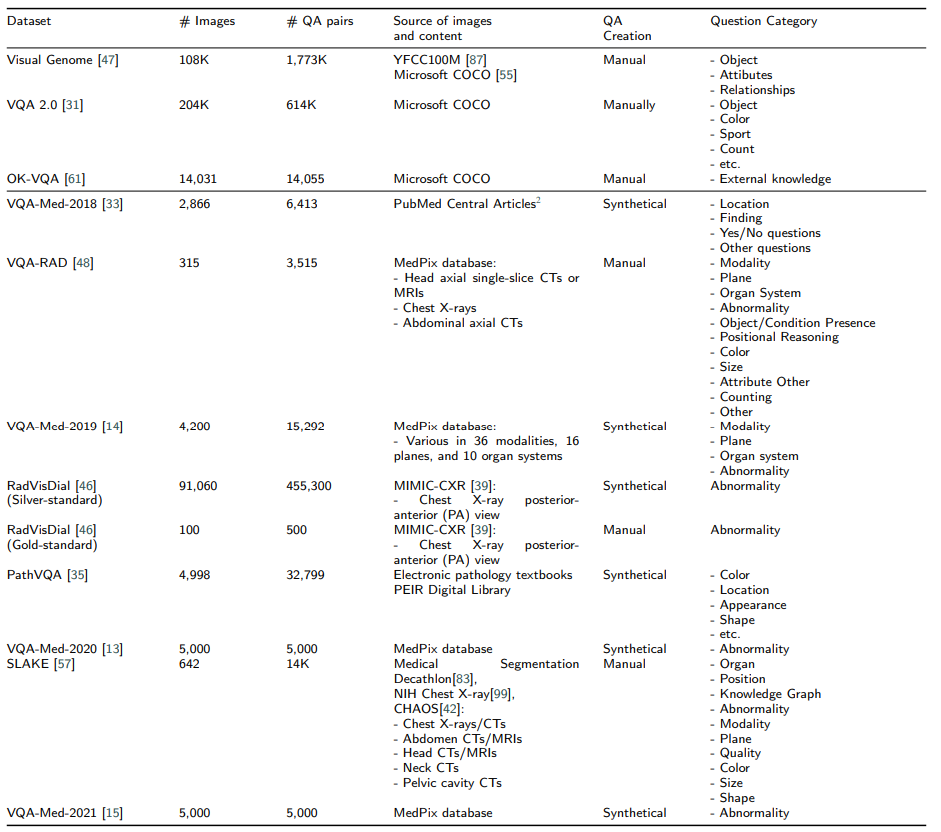
(1) 8개의 공식적으로 사용가능한 데이터셋이 있는데, 다음과 같다.
- VQA-MED-2018
- VQA-RAD
- VQA-MED-2019
- RadVisDial
- PathVQA
- VQA-MED-2020
- SLAKE
- VQA-MED-2021
(2) VQA-MED-2018

- VQA-MED-2018은 medical 도메인에서 처음 공식적으로 사용된 데이터 셋이다.
- ImageCLEF 2018에서 처음 제안되었다.
- 먼저 rule-based로 질문 생성하는 시스템을 통해 자동으로 (질문, 대답) 페어를 만든다.
- 그 후 의료 전문가를 포함한 annotator가 직접 모든 페어를 보고 옳바른 페이인지 확인한다.
(3) VQA-RAD

- VQA-RAD는 2018년에 나온 영상의학(radiology)에 특화된 데이터셋이다.
- 실제 상황을 최대한 반영하기 위해 annotator들이 자유로운 형식 및 template을 사용한 형식 두 가지를 사용해 데이터를 생성하도록 했다.
(4) VQA-Med-2019

- ImageCLEF 2019에서 제안되었다.
- VQA-RAD에 영감을 받아 4가지 주요한 카테고리에 대한 데이터를 포함했다.
- a. modality / b.plane / c.organ system / d.abnormality
- modality, plane, organ system은 분류(classification) 태스크 형식의 질문이고 abnormality는 생성(generation) 태스크 형식의 질문이다.
(5) RadVisDial

- RadVisDial은 영상의햑 분야에서 단순히 (질문, 대답)이 아닌 여러 번의 질문과 대답이 포함된 첫 번째 데이터셋이다.
- 여기서 사용된 이미지는 MIMIC-CXR에서 선택했다.
- MIMIC-CXR의 경우 14개의 라벨로 구성되어 있다. (13개의 abnormalitites와 1개의 No Findings)
- RadVisDial의 경우 silver-standard dataset / gold-standart dataset 두 개의 데이터셋으로 구성되어 있다.
- silver-standard dataset의 경우 이미지와 질문에 대해 단순히 4가지 선택지 중에서 고른 답변(yes, no, maybe, not mentioned)을 이용해 만들어진 데이터다.
- gold-standard dataset의 경우 두 영상의학 전문의로부터 생성된 (질문, 답변)으로 만든 데이터다. 랜덤으로 선택한 100개의 이미지에 대해서만 이 작업을 수행했다.
(6) PathVQA

- PathVQA는 병리 이미지를 활용한 데이터셋이다.
- 전자책과 전자 도서관으로부터 추출된 정보를 활용해 (질문, 답변) 페어 데이터를 생성했다.
- 질문은 총 7개의 종류로 나눌 수 있는데, (what, where, when, whose, how, how much/how many, yes/no) 이다.
- 개방형 질문이 50.2%, 폐쇄형 질문이 49.8%이다.
- 답변이 'yes'인 질문이 8145개, 답변이 'no'인 질문이 8189개이다.
- 본 데이터셋의 의도는 일종의 AI가 병리학자(Pathologist)가 될 수 있는지에 대한 시험용 데이터라 볼 수 있다.
(7) VQA-Med-2020

- VQA-Med-202은 VQA-Med 시리즈의 세 번째 데이터셋이며, ImageCLEF 2020에서 제안되었다.
- 질문은 이상치(abnormality)에 대한 것만 다루었다.
- 330개의 이상치에 관한 질문을 사용했으며, 각 질문이 데이터셋에 최소 열 번 이상 등장한다.
- VQA-Med-2020에서 visual question generation(VQG) 태스크가 medical 도메인에서 처음 소개되었다.
- 여기서 medical VQA 데이터셋은 1001개의 영상의학 이미지와 2400개의 연관 질문이 포함되었다.
(8) SLAKE

- SLAKE 데이터셋에서 이미지는 세 가지 open source dataset에서 가져왔으며, 경험 많은 의사로부터 (질문, 답변) 페어 데이터를 생성하였다.
- 의학 지식 정보도 같이 만들었는데, knowledge graph 형식으로 만들었으며 그 예시는 다음과 같다.
<Heart, Function, Promote blood flow>
- knowledge graph를 활용하여 조금 더 세부적인 질문에 대한 (질문, 답변) 페어 데이터를 생성할 수 있었다.
(9) VQA-Med-2021

- VQA-Med-2021은 ImageCLEF 2021에서 제안되었다.
- VQA-Med-2020과 기본적으로 같은 원리로 제장되었으며, training set은 VQA-Med-2020과 같다.
- validate set과 test set은 의학 전문가로부터 새롭게 만들어졌다.
(10) overall
- 맨 위의 Visual Genome, VQA 2.0, OK-VQA는 medical이 아닌 general한 VQA 데이터셋이며, 비교를 위해 넣었다.
(11) 정리
- 지금까지 8개의 medical VQA 데이터셋을 살펴보았다.
- 데이터셋의 크기는 315부터 91060까지 다양했으며, 한 개의 이미지당 1개의 QA 페어가 있는 것도 있고 10개의 QA 페어가 있는 것도 있었다.
- 이미지의 종류에는 흉부 X-ray / CT / MRI / pathology가 있었다.
*pathology는 병리 이미지를 의미
- VQA-RAD, VQA-Med-2019, VQA-Med-2020, VQA-Med-2021은 MedPix 데이터베이스를 기반으로 만들어 졌다.
- 또 RadVisDial은 MIMIC-CXR 데이터셋을 바탕으로 만들어졌으며, 병명이 라벨로 붙어 있는 유일한 가장 큰 medical VQA 데이터셋이다.
- 대용량의 medical VQA 데이터셋을 만드는 것은 쉽지 않은 일인데, 왜냐하면 의료 분야에 대한 전문 지식이 필요하기 때문이다.
- 최근에는 LLM의 발달로 데이터셋 제작할 때 LLM을 이용할 수 있게 되었다.
- medical VQA 데이터셋에서 또다른 문제는 환자의 수준에서 만들어진 (Question, Answer) 페어 데이터셋이 없다는 것이다. VQA-RAD의 경우 의학 계열 학생들로부터 만들어진 유일한 데이터셋이며, 다른 데이터셋의 경우 실제 의료 현장에서 사용되는 질문 및 답변을 바탕으로 구성되지 않은 경우가 많았다.
- 현재 medical VQA 데이터셋의 경우 영상의학과 병리학 쪽의 데이터만 있는데, 다른 분야에서도 사용될 여지가 많다.
3. medical VQA - 방법론
(1) medical VQA 태스크에서 사용된 방법론에 관한 내용을 찾기 위해 ImageCLEF 대회와 관련된 논문 및 Google Scholar를 활용해 medical VQA와 관련된 연구를 모았다.
(2) 총 217의 연구 논문을 찾을 수 있었고, 그 중에서 45개의 논문에서 46개의 방법론을 수집했다.
(3) 대부분의 방법론은 다음과 같은 4가지 항목으로 구성된다.
- image encoder
- question encoder
- feature fusing algorithm
- answering component
(4) image encoder로 사용된 모델은 주로 CNN 기반의 VGG Net, ResNet이다.
(5) question encoder로 사용된 모델은 주로 LSTM과 Transformer 기반의 모델들이다.
(6) image encoder와 question encoder에서 초기 값은 주로 사전 학습된 가중치(pretrained weights)를 이용했으며, 추가로 학습하는 동안(fine tuning) 사전 학습 가중치를 업데이트 하지 않는 경우와 업데이트 하는 경우 둘 다 있었다.
(7) feature fusing algorithm으로는 attention mechanism이 최근에 많이 사용되었다.
(8) answering component로는 neural network classifier 또는 recurrent neural network language generator가 주로 사용되었다.
4. Image Encoder
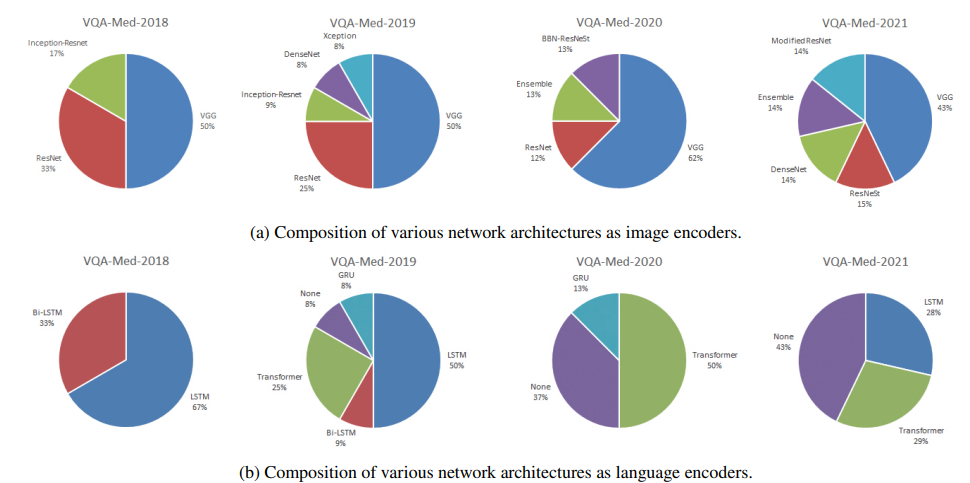
(1) 앞서 언급한 것처럼, image encoder로는 VGG net이 많이 사용된다.
(2) 더하여 46개의 방법론 중 29개의 방법론에서 ImageNet을 통해 얻어진 pretrained weights를 초기값으로 사용한다.
(3) 사실 medical VQA 태스크를 위한 데이터셋의 크기는 보통 5000개보다 적다. 즉, image representation을 학습시키기에 충분한 데이터가 없다는 문제가 있다.
(4) 따라서 이러한 문제의 해법으로 다음과 같은 방법들이 제안되었다.
- using other pre-trained models
- using extra dataset
- contrastive learning
- multi-task pre-training
- meta-learning
(5) 예시
- LIST 팀의 CheXpert 데이터셋으로 사전 학습된 모델 사용
- MMBERT 팀의 ROCO (이미지, 설명) 데이터셋 사용
- CPRD 팀의 contrastive learning을 활용한 unlabeled 데이터에서의 self-supervised learning
- MTPT-CSMA 팀의 segmetation task 활용
- MFVF팀의 Mixture of Enhanced Visual Feature(MEVF)를 활용한 Model-Agnostic Meta-Learning(MAML)
5. Language Encoder
(1) language encoder로는 LSTM, Bi-LSTM, GRU, Transformer(BERT, BioBERT를 포함) 등의 모델들이 사용되었다.
(2) 인상적인 점은 최근 가장 좋은 성능을 낸 모델들은 전부 BERT 기반의 모델들이라는 것이다.
(3) 대부분의 방법론에서 기존의 사전 학습된 weight를 추가 학습 없이 사용했으며, MMBERT 팀만이 Masked Language Modeling을 통한 추가 학습을 했다.
(4) image encoder에 비해 language encoder의 경우 많은 연구가 이루어지지는 않았다.
(5) 특히, 7팀은 question을 encoding할 때 deep learning 모델을 사용하지 않고 keyword matching 방식이나 template matching 방식을 사용했다.
6. Fusion Algorithm
(1) fusion algorithm은 앞선 image encoder와 language encoder를 통해 획득한 visual feature와 language feature를 합치는 것으로, VQA 방법론에서 핵심 중 하나이다.
(2) 전형적인 fusion algorithm은 attention mechanism과 pooling module이다.
(3) Attention mechanism
- 46개의 방법론들 중 24개의 방법론에서 attention mechanism을 활용하였다.
- 특히 Stacked Attention Networks (SAN)이 주로 사용되었는데, 이 방법론은 question feature를 query로 하여 answer과 관련된 이미지 feature 찾고 ranking을 매기는 방법론이라 할 수 있다.
- SAN 외에 Bilinear Attention Networks, Hierarchical Question-Image Co-Attention 등이 사용되었다.
- 흥미로운 점은 가장 유명한 attention mechanism인 multi-head attention module은 medical VQA에서 잘 사용되지 않았다는 것이다.
(4) Multi-modal pooling
- 기본적으로 concatenation, sum, element-wise product 방식을 포함한다.
- concatenation이 가장 많이 쓰이는 fusion method지만, 성능은 중간 정도이다.
- Multi-modal Compact Bilinear (MCB) pooling 방식이 제안되었는데, 이 방식은 Fourier space를 활용함으로써 외적(outer product)을 이용하는 것보다 효율적이다고 알려져 있다.
- 다른 방식으로는 Multi-modal Factorized Hight-Order (MFH) pooling, Multi-modal Factorized Bilinear (MFB) pooling이 있으며, VQA-Med-2018과 VQA-Meddd-2019에서 MFB pooling과 attention을 함께 사용한 방식이 가장 좋은 성능을 냈다.
- 또다른 방식으로는 QC-MLB, Med-FuseNet이 있는데 두 방식 모두 attention 기반의 새로운 방법론을 제시했으며, 기존의 성능에서 향상된 성능을 보여준 방식이다.
7. Answering Component
(1) answering component로 46개의 방법론 중에서 33개의 방법론이 classification 방식을 이용했고, 8개의 방법론이 generation 방식을 사용했다.
(2) classification 방식은 answer이 짧을 경우에 사용하기에 용이하지만, 반대로 answer이 길거나 복잡한 경우 사용하기 힘들다는 단점이 있다.
- ex. answer이 질환 부위를 설명하는 경우 (lesion descriptions)