
이 글에서는 2021년 1월 5일 발표된 논문인 Learning Transferable Visual Models From Natural Language Supervision에 대해 살펴볼 예정이다.
본 논문은 ChatGPT를 비롯한 GPT 모델 시리즈를 발표한 OpenAI로부터 발표되었으며 2021년 ICML에 Accept 되었으며, 현재(2023.8) 기준 인용수는 7004회이다.
논문 링크: https://arxiv.org/abs/2103.00020
Learning Transferable Visual Models From Natural Language Supervision
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual co
arxiv.org
0. Abstract
(1) 현재 가장 좋은 성능을 내는(SOTA) 컴퓨터 비전 모델은 특정 카테고리 내에서 [이미지, 라벨] 같이 고정된 형태의 데이터를 이용해 학습된다.
(2) 고정된 형태의 데이터를 이용해 컴퓨터 비전 모델을 학습시키는 것은 모델의 일반화 성능(generality)과 다른 태스크에서의 사용 가능성(usability) 제한한다.
* 고정된 형태의 데이터란 :
- 특정 카테고리 내에서
- 간단하고 짧은 라벨 텍스트만 붙은
(3) 따라서, 이미지와 이 이미지를 설명하는 조금 더 상세한 텍스트(raw text)를 라벨로 사용한다면 기존의 컴퓨터 비전 데이터의 문제를 해결할 수 있을 것이다.
(4) 우리는 이 방법론의 성능을 30개의 다른 벤치마크 데이터셋을 이용해 조사했으며, 그 예로는 다음과 같은 것이 있다.
- OCR
- action recognition in videos
- geo-localization
- many types of fine-grained object classification
*fine-grained object classification이란 자동차의 모델 , 새의 종류, 개의 종류 등과 같이 구분하기 어려운 클래스들을 분류하는 과제를 말한다.
(5) 이 방법론을 적용한 모델은 다양한 태스크에서 좋은 성능을 낸다. 즉, 추가적인 데이터셋을 활용하지 않고도 특정 태스크를 위해 추가적인 데이터셋으로 학습한 기존 모델들과 견줄만한 성능이 나온다는 것이다.
(6) 모델의 코드와 사전 학습 weight는 다음 사이트에서 확인할 수 있다.
- https://github.com/OpenAI/CLIP
1. Introduction and Motivating Work
(1) 자연어처리 분야에서, raw text를 이용해 사전 학습을 하는 방식은 계속 발전해왔다.
(2) Masked Language Modeling을 통한 task에 구애받지 않는(task-agnostic) 학습은 모델이 대규모의 데이터를 이용해 학습할 수 있도록 만들었다.
(3) 추가로 "text-to-text" 방식을 사용하게 됨으로써 태스크마다 다른 토큰을 사용하는 등의 추가적인 작업을 할 필요도 없어졌다.
(4) 이러한 발전된 사전 학습 방법을 모두 적용한 모델인 GPT-3는 라벨링된 데이터셋 없이도 다양한 태스크에서 좋은 성능을 내는 모델이 되었다.
(5) 즉 자연어처리 분야에서는 적은 양의 라벨이 붙은 고품질 데이터셋보다, 많은 양의 웹 상에서 수집된 라벨이 없는 데이터가 더 학습에 용이하게 사용된다는 것이다.
(6) 하지만, 컴퓨터 비전과 같은 분야에서는 적은 양의 라벨이 붙은 고품질 데이터셋을 이용해 계속 학습한다.
(7) 자연어처리 분야처럼 웹 상에서 수집된 테스트로부터 사전 학습을 하는 방식을 컴퓨터 비전 분야에 적용해 혁신을 가져올 수 있을까?
(8) 선행 연구들을 본다면 가능하다고 볼 수 있다.(Prior work is encouraging)
(9) text로부터 image representation을 학습시키는 방법론은 이전부터 있어 왔으며, 최근의 방식은 transformer-based의 language modeling, masked language modeling 및 contrastive objectives를 이용하는 것이다.
(10) 그러나 text로부터 image representation을 학습시키는 방법론을 사용한 연구가 많지는 않은데, 그 이유는 다른 방법론에 비해 성능이 좋지 않았기 때문이다.
(11) 예시로, text로부터 image representation을 학습시키는 방법론인 Learning Visual N-Grams from Web Data, Li et al., 2017에서 ImageNet의 정확도가 11.5%밖에 되지 않았는데, 가장 좋은 성능(SOTA)은 88.4%기 때문이다.(Self-training with Noisy Student improves ImageNet classification, Xie et al., 2020)
(12) 대신, weak supervision에서 사용은 성능의 향상을 보였다.
(13) weak supervised 모델과 최근 연구되는 자연어처리를 이용한 image representation 모델과의 차이점은 크기(scale)이다.
(14) 최근 모델들은 수백만에서 수십억 개의 이미지를 이용해 학습하지만, VierTex, ICMLM, ConVIRT와 같은 이전의 weak supervised 모델들은 20만 개의 이미지만을 이용해 학습되었다.
(15) 최근에는 웹 상으로부터 데이터를 얻기가 더 쉬워졌기에 우리는 4억개의 [이미지, 텍스트] 페어를 만들었으며, 이를 ConVIRT의 간단한 버전을 이용해 학습했는데, 이를 Contrastive Language-Image Pre-training, 줄여서 CLIP이라 부르기로 했다.
(16) GPT 모델들과 같이, CLIP도 다양한 분야의 태스크에 적용할 수 있었으며, 특정 태스크만을 위해 만들어진 모델과 비교도 할 수 있음을 알게 되었다.
(17) 특히 linear-probe 방식을 이용한 파인 튜닝에서 CLIP 모델이 다른 모델들보다 성능이 좋을 뿐만아니라 효율적이라고 말한다.
(18) 또한 zero-shot CLIP 모델이 같은 정확도를 가지는 다른 모델보다 더 robust하다고도 언급한다.
2. Approach
2.1 Natural Language Supervision
(1) 본 연구에서 제시하는 방법의 핵심은 자연어를 이용한 지시(Natural LanguageSupervision)이다.
(2) 이전에도 본 연구에서 사용한 방법론을 이용한 학습은 있어왔지만 각각 부르는 이름이 달랐다.(unsupervised, self-supervised, weakly supervised, supervised ...)
(3) 자연어를 이용한 방법론은 이점이 있는데 그 이점은 다음과 같다.
- scale을 키우기가 쉽다.
*이전의 방법론에서는 scale을 키우기 위해서는 일일이 라벨링된 데이터를 많이 만들어야 했다.
- 단순히 이미지를 텍스트로 표현(representation)하도록 학습하는 것이 아니라 모델이 이미지에 대해 조금 더 깊은 이해를 가질 수 있게 해 'zero-shot transfer'를 가능할 수 있게 해준다.
(4) zero-shot transfer와 관련해서는 아래 내용에서 자세히 설명할 것이다.
2.2 Creating a Sufficiently Large Dataset
(5) 이때까지의 연구들은 주로 세 가지 데이터셋을 사용했다.
- MS-COCO
- Visual Genome
- YFCC100M
(6) MS-COCO와 Visual Genome은 양질의 라벨링된 데이터셋이지만 그 양이 각각 대략 10만개 정도로 많지 않다.
(7) 대조적으로, 다른 컴퓨터비전 분야에서 사용하는 데이터셋의 크기는 훨씬 큰데, 35억개의 인스타그램 사진(Exploring the Limits of Weakly Supervised Pretraining, Mahajan et al., 2018)을 이용해 학습하기도 한다.
(8) YFCC100M 데이터셋은 1억개의 사진을 가지고 있어서 비교적 양이 많기는 하지만, 비교적 양질의 데이터가 아니다.
(YFCC100M, at 100 million photos, is a possible alternative, but the metadata for each image is sparse and of varying quality)
(9) 따라서, 본 연구에서는 새로운 데이터셋을 새로 만들었는데, 약 4억개의 (image, text) 페어로 구성되어 있고 모든 데이터는 인터넷에서 수집한 데이터이다.
(10) 데이터의 다양성을 얻기 위해, 5만 개의 텍스트 쿼리를 이용했으며, 하나의 쿼리에서 2만 개가 넘는 (image, text) 페어를 갖지 않도록 했다.
*즉 쿼리를 이용해 텍스트-이미지 매칭을 한 뒤, 페어를 만들어주는데, 한 쿼리당 페어 이미지가 2만개를 넘지 않도록 함
(11) 사용된 데이터셋의 총 단어 수는 GPT-2에서 사용된 WebText에서의 양과 유사하다.
(11) 본 연구에서 사용한 데이터셋을 WebImageText, WIT라 부르기로 한다.
2.3 Selecting an Efficient Pre-Training Method
(12) 기존의 연구에서는 ImageNet 데이터에서 단지 1000개 class 분류를 위해 매우 많은 GPU 메모리를 사용하였다.
(13) 따라서 본 연구에서는 효율적으로 학습하는 것이 중요한 조건이라 생각하고 이를 항상 고려하도록 하였다.
(14) 본 연구의 초기 접근 방법은, VirTex와 유사하게 이미지는 CNN으로, 텍스트는 transformer를 이용해 학습시키고 각각 이미지에 대해 이미지의 설명 텍스트(caption)를 예측하는 태스크를 수행했다.
(15) 그러나, 이 방법으로는 효과적으로 모델의 크기(scale)을 증가시키기 어려웠다.
(16) 본 연구에서는 이미지에 해당하는 텍스트를 예측하는 태스크를 수행할 때의 과정을 수정해 효율적인 학습이 가능하도록 했다. 그 방법은 다음과 같다.
(17) 기존의 방식에서는 텍스트 문장을 예측할 때 그 문장 그대로, 즉 단어의 순서까지 정확 맞추는 태스크로 학습했는데, 본 연구에서는 순서는 고려하지 않고 예측할 수 있도록 bag-of-words encoding을 사용해 contrastive learning을 했다.

(18) 위 figure를 보면 알 수 있듯, 이를 통해 훨씬 효율적인 학습이 가능하도록 했다.
(19) 학습 방식은 다음과 같다.

a. 기본적으로 배치 단위로 학습이 이뤄지는데, 예를 들어 배치 사이즈가 N이라고 하면 N개의 (image, text) 페어가 있는 것이다.
b. 텍스트는 Text Encoder를 이용해 벡터 값으로 표현되게 되고, 이미지는 Image Encoder를 이용해 벡터 값으로 표현되게 된다.
c. N개의 텍스트 벡터와 N개의 이미지 벡터 사이의 코사인 유사도를 구한다.
d. 총 $N*N = N^2$개의 값이 나오는데 $N$개는 실제 (image, text) 페어에서 나온 값이고 $N^2-N$개는 다른 (image, text)페어에서 나온 값이다.
e. 이 유사도 값을 이용해 Cross Entroy loss 값을 계산해 최적화 한다.
(20) pseudocode는 다음과 같다.

(21) 본 연구에서 사용된 데이터셋의 개수가 많기 때문에 over-fitting 문제는 고려하지 않았다.
(22) 따라서 CLIP의 Text Encoder와 Image Encoder에서 다른 pre-trained weight나 ImageNet weight를 사용하지 않고 처음부터 학습시켰다.
(23) 이전의 연구들과 다르게 image와 text represention을 multi-modal embedding으로 보낼 때 non-linear projection을 하지 않고 linear하게 projection을 하였다. (*np.dot(I_f, W_i), np.dot(T_f, W_t))
*그 이유로 non-linear와 linear 두 버전을 보았을 때 학습 효율적인 측면에서 차이가 없었기 때문이라 밝히고 있다.
2.4 Choosing and Scaling a Model
(24) 본 연구에서는 Image Encoder로 두 가지 다른 모델을 이용했다.
- ResNet-50
- Vision Transformer(ViT)
(25) Text Encoder로는 Transformer를 이용했다.
(26) 이전의 컴퓨터비전 연구는 모델의 너비와 깊이 중 하나만 이용해 모델을 확장했지만 본 연구에서 ResNet Image Encoder의 경우 너비, 깊이, 해상도 모두 확장했다.
*너비, 깊이, 해상도 모두 확장해 추가적으로 compute하는 것이 성능이 우수하다는 것을 알게 되었다.
(27) 또 Text Encoder의 경우 Resnet 너비에 맞춰주긴 했으나, 추가적으로 깊이를 증가시키지는 않았는데, CLIP의 성능이 Text Encoder의 크기에 덜 민감하다는 것을 알게 되었기 때문이다.
2.5 Training
(28) 5가지의 ResNet 모델을 사용했으며, 3가지의 Vision Transformer 모델을 사용했다.
- ResNet-50
- ResNet-101
- 3 more EfficientNet-style model (4x, 16x, 64x of ResNet-50, denoted as RN50x4, RN50x16, RN50x64)
- ViT-B/32
- ViT-B/16
- ViT-B/14
(29) 효율적인 학습을 위해 몇 가지 방법을 사용했는데, 다음과 같다.
- use minibatch size of 32,768
- gradient checkpointing
- half-precision Adam statistics
- half-precision stochastically rounded text encoder weights
(30) 가장 큰 ResNet 모델인 RN50x64로 학습시키는데 592대의 V100을 이용해 18일이 걸렸다.
(31) 가장 큰 ViT 모델에서는 256대의 V100을 이용해 12일이 걸렸다.
3. Experiments
*(0) 논문에서 진행된 실험 및 연구 내용이 너무 방대하기에 중요하다 판단되는 부분만 추려서 소개하고자 한다.
3.1 Zero-Shot Transfer
(1) 본 연구에서 정의하는 zero-shot transfer란, 학습 때 사용하지 않은 데이터셋에 대해 image classification을 하는 태스크를 의미한다.
(2) 또 본 연구에서 밝히길, image classification에서 zero-shot tranfer를 처음 사용한 연구는 Visual N-Grams라 한다.
(3) Visual N-Grams와 CLIP의 성능을 비교하면 다음과 같다.

(4) 모든 데이터셋에 대해 CLIP 모델을 통해 성능이 향상된 것을 알 수 있다.
(5) prompt engineering에 대해 말하자면 GPT-3 논문에서 밝히듯, prompt를 잘 짜는 것만으로도 zero-shot 성능을 상당히 높힐 수 있다는 것을 알게 되었다.
(6) 따라서 본 연구에서 prompt를 사용했는데, 여러가지 데이터셋에서 "A photo of a {label}"과 같은 형식의 prompt를 default로 사용했다.
(7) 또 ImageNet에서는 80개의 다른 prompt를 사용하는 것이 하나의 dafault prompt를 사용하는 것보다 3.5%의 성능향상이 있었다.
(8) 종합하면 prompt engineering을 사용함으로써 5% 정도의 성능 향상을 만들 수 있었다. 아래의 figure에서 확인할 수 있다.

(9) CLIP의 성능을 확인하기 위해, Linear Probe 방식을 통해 fine tuning을 시킨 ResNet-50 모델과 여러가지 데이터셋에 대해 성능을 비교했는데 그 결과는 아래 figure와 같다.
*Linear Probe 방식은 모델의 파라미터는 그대로 두고, 모델의 맨 마지막 출력 부분에 Classification을 위한 Linear layer만 추가해 그 부분만 학습시키는 방법으로 이해했다.

(10) 총 27개의 데이터셋 중, 16개의 데이터셋에서 CLIP이 더 좋은 성능을 보여주었다.
(11) CLIP이 더 약한 성능을 보인 데이터셋을 살펴보면 더 복잡하거나 추상적인 태스크를 가진 데이터셋이었다.
(12) 제일 성능 차이가 심한 EuroSAT은 인공위성 이미지를 분류하는 태스크이다.
(13) Supervised learning을 한 모델(ResNet-50)과 그렇지 않은 모델(CLIP)을 비교한 것이기에 CLIP에서 성능이 좋지 않다고 나온 태스크를 CLIP이 정말 못 한다고 단정지을 수는 없다.
(14) 따라서 추가로 zero-shot CLIP 모델을 few-shot 모델들과 비교했는데, 그 결과는 다음과 같다.

(15) SimCLR와 비교하면 16-shot SimCLR가 Zero-shot CLIP과 성능이 비슷한 것을 알 수 있었다.
3.2 Representation Learning
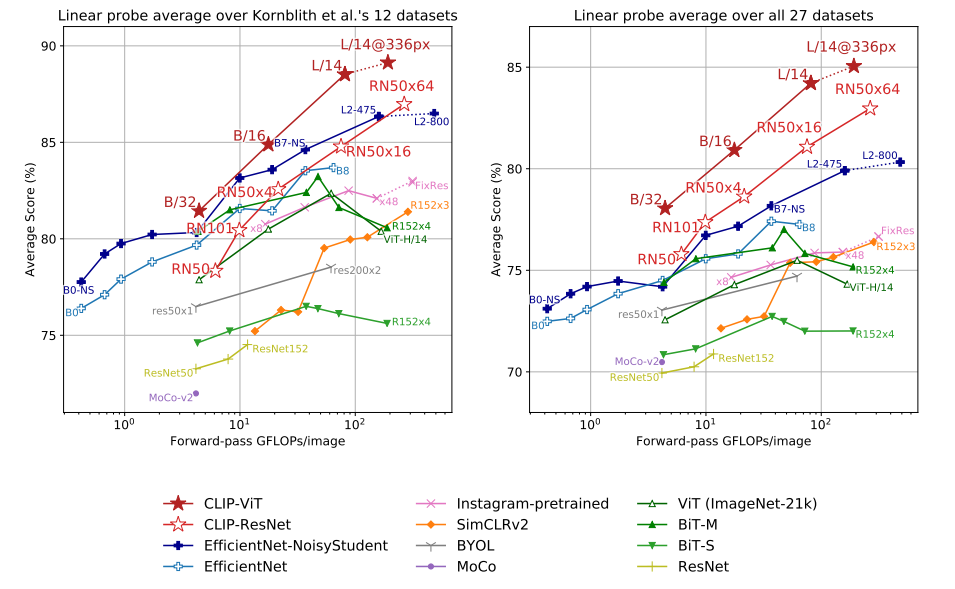
(16) CLIP을 포함한 모든 모델에 Linear probe를 이용한 성능을 비교한 figure이다. 각각 12개, 27개의 데이터셋에 대한 점수를 평균낸 것이다.
(17) 모든 크기에서 CLIP모델이 다른 모델보다 좋은 성능을 냈다.
3.3 Robustness to Natural Distribution Shift
(18) 2015년, ImageNet 대회에서 deep learning 모델이 인간을 뛰어넘었다고 발표했다.
(19) 그러나 밝혀진 연구에 따르면 이 모델들은 여전히 간단한 태스크라도 실수를 하는 낮은 성능을 보여주었으며, 심지어 새로운 벤치마크 데이터에서는 인간보다 좋지 않은 정확도를 내기도 했다고 한다.
(20) 왜 성능저하가 나타나는지 밝혀보니 소위 over-fitting이라 불리는, 즉 모델이 학습 데이터를 다 외워버렸기 때문에 비슷한 분포의 데이터(in-distribution) 에서만 좋은 성능을 냈던 것이다.
(21) 이러한 측면에서 살펴보면, CLIP 모델은 다른 분포의 데이터에 대해서도 훨씬 견고함(robustness)을 가진다고 볼 수 있다.
*아래 figure는 ImageNet 점수와 다른 태스크에서의 점수(Transfer Score)와의 비교 관계를 나타낸 것이다.

4. Comparison to Human Performance
(1) 인간의 성능을 측정하기 위해, 본 연구에서는 5명을 대상으로 Oxford IIT Pets dataset에서 3669개의 이미지를 보고 37개의 class로 classification을 하도록 시켰다.

(2) 흥미로운 것은, 인간의 성능을 보게 되면 Zero-shot에서 One-shot으로 갈 때는 유의미한 성능 향상이 있지만 One-shot에서 Two-shot으로 갈 때는 성능 변화가 미미하다는 것이다.
(3) 이것이 의미하는 것은 인간은 자기가 무엇을 알고 무엇을 모르는지 알고 있다는 것이다.
*Zero shot에서 몰랐던 내용 중 예시 하나만 주어져도(One-shot) 알게 되는 내용이 생기지만, 예시를 추가한다고 해서 더 알게 되지는 않은 것으로 보아 이렇게 추측한 것으로 이해했다.
(4) CLIP은 이와 다른게 shot을 늘려갈수록 성능이 계속 증가한 것으로 보아, 알고리즘적으로 개선할 여지가 있다고 판단한다.
5. Limitations
(1) 먼저, 특정 태스크에서는 CLIP이 여전히 좋지 않은 성능을 보인다는 것이다.
(2) 특히 차의 모델 분류, 꽃의 종 분류 등 태스크가 복잡한(fine-grained classification) 경우 조금 더 성능 저하가 심했다.
(3) 또 CLIP은 인터넷 상에서 가져온 (image, text) 페어를 통해 학습되었는데, 필터링이 되지 않았다는 문제가 있다.
(4) 이에 따라 social biases를 그대로 학습할 수 있다.
(5) 더하여 앞선 human performance와 비교 실험에서 살펴보았듯이, CLIP에서 zero-shot 성능을 더욱 상승시킬 수 있는 few-shot 방법에 대해 후속 연구가 필요하다.
*Commentary
- 지금까지 CLIP 모델을 발표한 논문을 살펴보았다.
- 개인적으로 multi modal model에 대한 논문을 처음 읽어 보았는데, CLIP의 방법론이 간단함에 비해 성능이 잘 나오는 것이 신기했고 더 최근의 모델들은 어떤 방법을 썼을 지 궁금해졌다.
- 논문의 전체 페이지가 48페이지에 본문만 27페이지로, 비교적 긴 논문이다. 그만큼 실험 과정에 대해 자세히 소개하고 있으니, 자세한 정보를 원한다면 논문을 발췌독해도 좋을 것 같다.